Нагрузка от ИИ ломает GitHub — почему другие вендоры держатся?
Надёжность GitHub в последнее время далеко вышла за пределы допустимого: в прошлом месяце сторонние измерения зафиксировали всего одну «девятку» — около 90%. В этом месяце показатель опустился до нуля «девяток» — 86%, согласно стороннему трекеру, а на прошлой неделе всё стало ещё хуже: откровенно скандальный инцидент с целостностью данных, новые сбои и наконец-то частичные объяснения от GitHub.
Инцидент с целостностью данных
В прошлый четверг (23 апреля) произошло следующее: PR-запросы, смёрженные через очередь слияния (merge queue) методом squash merge, при наличии более одного PR в группе слияния порождали некорректные merge-коммиты. Коммиты из последующих слияний откатывались — то есть код, попавший в мёрж, фактически «терялся».
Из-за ошибки, которую внёс сам GitHub, сервис нарушил своё обязательство по целостности данных: pull request-ы должны мёржиться именно так, как ожидает пользователь, когда он применяет squash merge — технику, при которой несколько мелких коммитов объединяются в один осмысленный. Это серьёзная проблема: гарантии целостности данных — одни из важнейших для таких сервисов, как GitHub.
Всего пострадало 2 092 pull request-а; среди затронутых компаний — Modal и Zipline. По сути, GitHub переложил работу по устранению последствий на самих пользователей: те вручную разбирались в истории git и восстанавливали потерянные коммиты — и всё это без какой-либо помощи со стороны платформы.
Клиентам пришлось вручную просматривать git-историю и восстанавливать пропавший код. Следуя шагам ручного восстановления (откат squash-коммита и повторное применение коммитов по одному), в итоге всё удалось восстановить.
GitHub позднее отправил список затронутых коммитов клиентам по электронной почте, однако примечательно, что руководители GitHub, судя по всему, постарались преуменьшить серьёзность произошедшего. А ведь инцидент, затрагивающий целостность данных, несопоставимо серьёзнее банального снижения доступности, при котором данные не повреждаются.
Кан Дурук, инженер-программист в Modal, остался крайне недоволен вялой реакцией GitHub:
«Операционный директор изо всех сил ищет огромный знаменатель, чтобы масштаб проблемы казался меньше — это выглядит очень нечестно. Вместо этого стоило бы искренне извиниться за то, что произошедшее перечёркивает все их обязательства перед клиентами. Нам пришлось самим залезть на страницу статусов, чтобы вообще понять, что они только что небрежно сломали наш репозиторий.»
Сбои не прекращаются
В понедельник (27 апреля) pull request-ы и задачи (issues) пропали из веб-интерфейса GitHub:
Причиной стал сбой Elasticsearch на бэкенде GitHub: кластер перегрузился и упал. Таким образом, pull request-ы, задачи и проекты никуда не делись, но и не отображались на протяжении шести часов.
На той же неделе произошли и другие инциденты:
-
Часть pull request-ов не отображалась (вторник, 28 апреля)
-
Проблемы с GitHub Actions (в тот же день)
-
Неполные pull request-ы в репозиториях (среда, 29 апреля)
Также во вторник (28 апреля) компания по информационной безопасности Wiz раскрыла критическую уязвимость: злоумышленник мог получить доступ ко всем репозиториям на GitHub и GitHub Enterprise Server, использовав лишь команду git push. GitHub устранил проблему на GitHub.com в течение шести часов, однако серверы GitHub Enterprise, которые не были обновлены, по-прежнему остаются уязвимыми.
Известный опенсорс-разработчик уходит с GitHub
Во вторник Митчелл Хашимото (Mitchell Hashimoto), основатель HashiCorp и создатель Ghostty, объявил, что GitHub не подходит для профессиональной работы, и перенесёт проект Ghostty — опенсорсный терминал, которому посвящает основное время, — на другую платформу. Логика Митчелла предельно проста (выделение моё):
«Весь прошлый месяц я вёл дневник, где ставил «X» напротив каждого дня, когда сбой GitHub мешал мне работать. Почти каждый день — с крестиком. В день, когда я пишу этот пост, я уже около двух часов не могу проводить ревью PR из-за сбоя GitHub Actions. Место, которое блокирует тебя на несколько часов в день каждый день, — это больше не место для серьёзной работы.
Мне там уже некомфортно. Я хочу там быть, но платформа словно не хочет меня принимать. Я хочу делать работу, а платформа словно мешает мне её делать. Я хочу выпускать программный продукт, а платформа словно противится этому.
Я хочу, чтобы всё стало лучше, но мне ещё нужно писать код. А с GitHub я больше не могу этого делать. Извините. После 18 лет мне приходится уйти. Я с удовольствием вернусь когда-нибудь, но только если увижу реальные результаты и улучшения, а не слова и обещания.»
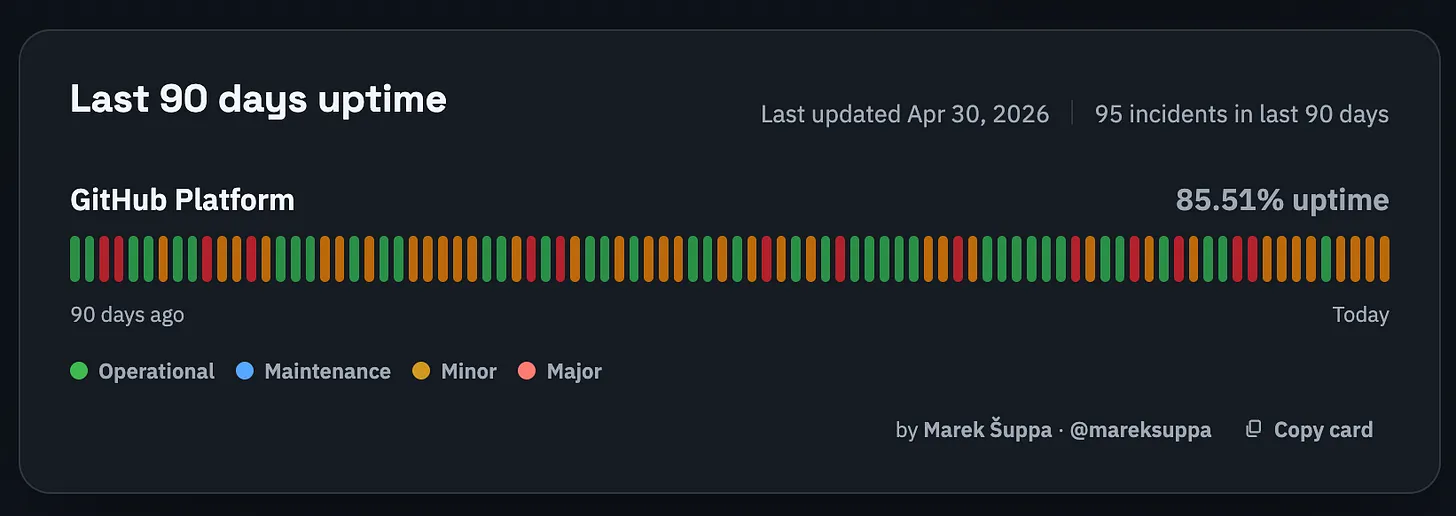
Опыт Митчелла говорит о том, что официальная страница статусов GitHub неточна с точки зрения активного пользователя. Сторонний ресурс «https://mrshu.github.io/github-statuses/?ref=blog.pragmaticengineer.com[недостающая страница статусов GitHub]» даёт, по всей видимости, более реалистичную картину: надёжность GitHub — ноль «девяток», uptime 85,51%. Это значит, что какая-то часть GitHub в среднем не работала по 2–3 часа в день на протяжении последних 90 дней (!).
Жалоба Митчелла понятна без лишних слов:
-
Профессиональному разработчику нужны инструменты, которые помогают работать, а не мешают.
-
Месяцами GitHub непрерывными сбоями тормозит его работу над опенсорс-проектами.
-
Нет смысла пользоваться продуктом, непригодным для профессиональной работы.
-
Поскольку GitHub не демонстрирует никаких признаков улучшения, имеет смысл перейти на решение, которое просто работает.
Технический директор винит всплеск нагрузки от ИИ-агентов
Технический директор GitHub Влад Фёдоров (Vlad Fedorov) опубликовал объяснение, почему надёжность платформы падает уже несколько месяцев. Виновником он назвал нагрузку от агентов, которая оказалась значительно выше ожидаемой. GitHub сопроводил публикацию иллюстрирующими графиками:
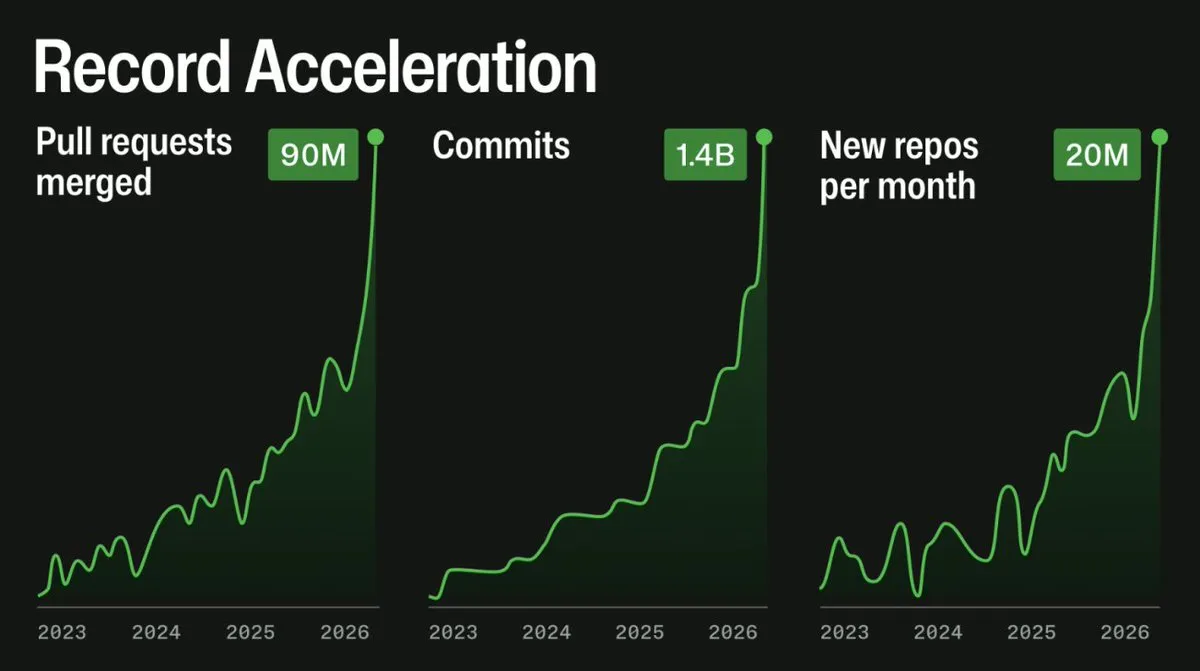
График выглядит эффектно — но есть одна маленькая проблема: ось Y отсутствует. То есть он показывает, что нагрузка сначала росла медленно, а потом очень быстро, но не говорит, насколько именно. Мне удалось получить данные от GitHub напрямую, и ниже представлен график с реальными цифрами роста нагрузки за два года:
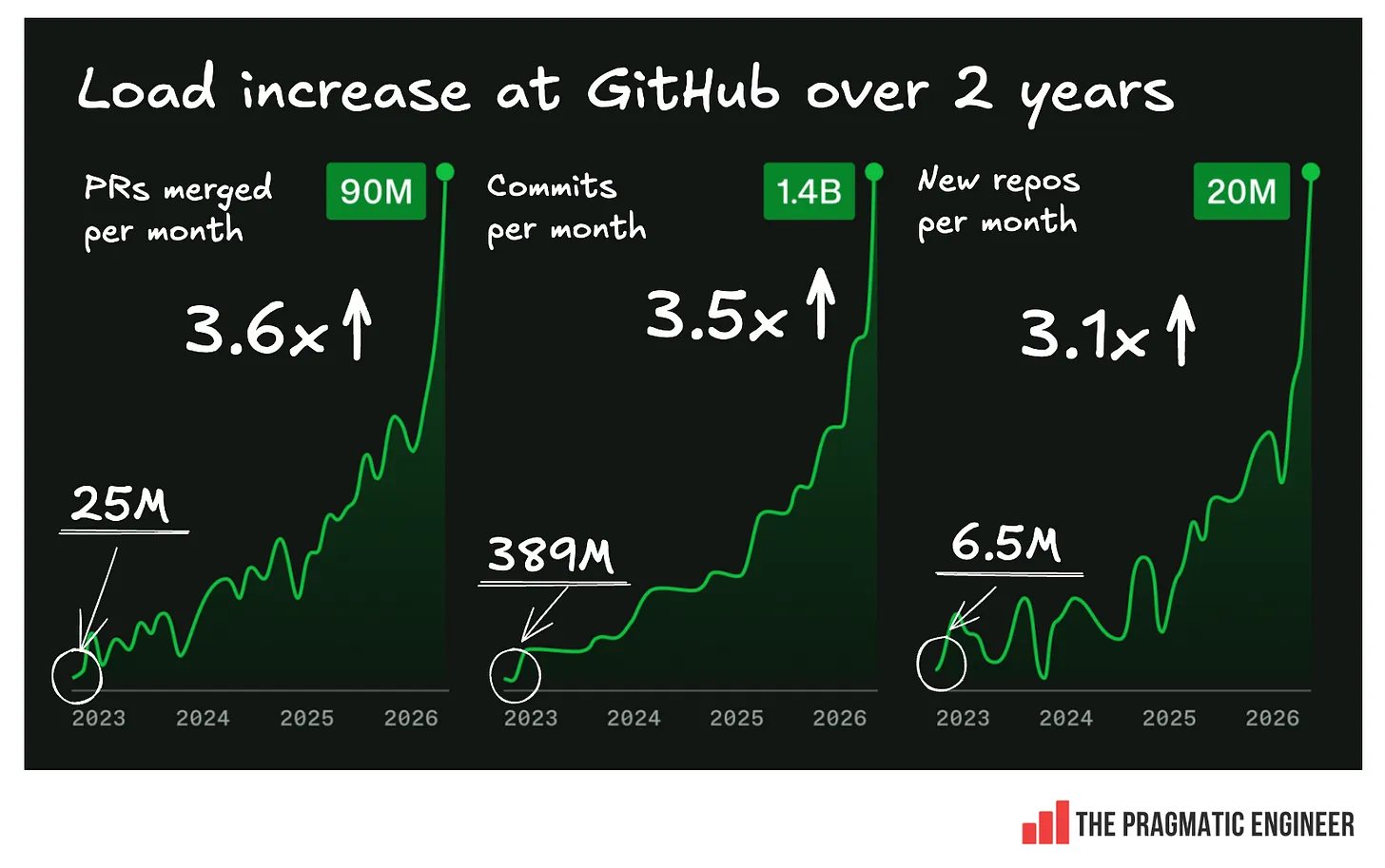
Рост нагрузки примерно в 3,5 раза за два года на первый взгляд не выглядит катастрофой. Это совсем не то же самое, что десятикратный рост за месяц, и значительная часть этого прироста пришлась на последние месяцы. Так почему же GitHub с этим не справляется? В своём блог-посте Фёдоров пишет:
«Один pull request может затрагивать хранилище Git, проверки возможности слияния (mergeability checks), защиту веток, GitHub Actions, поиск, уведомления, права доступа, вебхуки, API, фоновые задачи, кеши и базы данных. При большом масштабе даже мелкие неэффективности накапливаются: очереди растут, промахи кеша превращаются в нагрузку на базу данных, индексы не успевают обновляться, повторные попытки усиливают трафик, и одна медленная зависимость способна повлиять на несколько пользовательских сценариев.»
Вот как выглядит сравнение нагрузки в единицах запросов в секунду в январе 2023 года и сегодня:

На достижение показателей 2023 года GitHub потратил 15 лет и, вероятно, рассчитывал продолжать расти сопоставимыми темпами. Если так, то часть инфраструктурных решений, рассчитанных на долгую перспективу, с приходом ИИ-агентов просто устарела.
Помимо прочего, компания в разгаре миграции из собственных дата-центров в Azure. В октябре прошлого года GitHub приступил к переходу на Azure — проект рассчитан на 12 месяцев — из-за уже исчерпанных мощностей собственных дата-центров.
Крупномасштабные инфраструктурные миграции и при стабильной нагрузке требуют колоссальных усилий: нужно просто убедиться, что ничего не сломается. Когда же нагрузка при этом резко растёт, ошибки оборачиваются куда более заметными сбоями. Впрочем, теперь, понимая масштаб происходящего, GitHub сможет получить на Azure значительно больше вычислительных мощностей.
Но другие крупные компании заранее готовились к десятикратному росту инфраструктурной нагрузки — почему Microsoft и GitHub не сделали того же? Год назад я исследовал, как крупные технологические компании готовятся к влиянию ИИ на свой бизнес. Google совершенствовал внутренние системы с расчётом на десятикратный рост нагрузки. Как мы писали в The Pragmatic Engineer в июле прошлого года:
«Google готовится к тому, что объём поставляемого кода вырастет в 10 раз. Бывший инженер по надёжности сайтов (Site Reliability Engineer, SRE) Google рассказал мне: "Судя по тому, что я слышу от коллег-SRE, они готовятся к тому, что в продакшен будет попадать в 10 раз больше строк кода." Если какая-то компания и располагает данными о вероятном влиянии ИИ-инструментов, то это Google. В 10 раз больше сгенерированного кода, скорее всего, означает в 10 раз больше: ревью кода, деплоев, флагов функций, объёма в системах контроля версий и, возможно, даже ошибок и инцидентов — если не проявлять должной осторожности.»
Прогнозы о колоссальном росте нагрузки не были секретом в отрасли, однако GitHub, судя по всему, оставался в блаженном неведении об их реальных масштабах. По словам Влада, GitHub в итоге всё же запланировал увеличение мощностей в 10 раз, но лишь в октябре 2025 года — на несколько месяцев позже. В феврале 2026 года компания скорректировала эту оценку до 30 раз. Фёдоров написал:
«В октябре 2025 года мы приступили к реализации плана по увеличению мощностей GitHub в 10 раз, ставя цель существенно повысить надёжность и отказоустойчивость. К февралю 2026 года стало очевидно, что нам нужно проектировать инфраструктуру с расчётом на 30-кратный относительно сегодняшних показателей масштаб.»
Открытым остаётся и вопрос: не просчитался ли GitHub со временем, которое у него есть на подготовку к взрывному росту нагрузки, и не застал ли он компанию врасплох, когда в начале этого года тот рост наступил на несколько месяцев раньше ожидаемого?
Учитывая, что GitHub начал готовиться к масштабному росту нагрузки лишь в октябре, нынешние проблемы неудивительны. В компаниях масштаба GitHub каждая команда, отвечающая за сервис, как правило, планирует нагрузку на год вперёд, и в соответствии с этим выделяются аппаратные ресурсы: хранилища, виртуальные машины, сетевые мощности. Планирование нагрузки может занимать до половины всей подготовительной работы, и когда реальность расходится с планами, некоторые системы не справляются с масштабированием.
С одной стороны, рост нагрузки в 3,5 раза за два года не должен быть катастрофой для большинства сервисов — особенно для тех, которые хорошо масштабируются горизонтально (когда состояния мало и масштабирование достигается простым добавлением узлов). Но GitHub, судя по всему, хранит значительно больше состояния — в pull request-ах, рабочих процессах, проектах и т. д. Это, вероятно, сильно усложняет масштабирование баз данных и систем, выполняющих рабочие процессы.
К тому же за 18 лет GitHub накопил значительный технический долг и тысячи сотрудников, координация которых сама по себе создаёт «организационные издержки». По мере того как нагрузка на сервис растёт быстрее прежнего, реагировать становится труднее из-за накопленного «долга»:
-
Технический долг: многим системам компании уже более 10 лет, они, вероятно, поддерживаются заплатками, что делает изменения сложнее и рискованнее.
-
Организационный долг: в GitHub работает около 4 000 человек, из которых 1 000 — инженеры. Команды зависят друг от друга, и даже внешне простая задача может потребовать совместной работы десятков специалистов.
-
Ожидания клиентов: GitHub не может ломать привычные рабочие процессы клиентов, даже если это ускорило бы изменения в системах.
GitHub оказался в классической «дилемме инноватора» (innovator’s dilemma): компания добилась успеха, создав процессы разработки, которые идеально подходили для эпохи до ИИ, и умела точно прогнозировать изменения в нагрузке. Но теперь, когда в работу инженерных команд вошли ИИ-агенты, прежние подходы GitHub уже не являются оптимальными, а предсказывать изменения на уровне сервиса компания не смогла.
Другие вендоры не падают под нагрузкой ИИ
В этой ситуации есть одна деталь, которая не вяжется с остальным: другие вендоры, испытывающие, по всей видимости, схожий всплеск нагрузки, не страдают от проблем с надёжностью в той же мере. Vercel, Linear, Resend, Railway, Sentry и другие инфраструктурные провайдеры показывают рекордный рост благодаря ИИ и справляются с нагрузкой.
Да, у ИИ-вендоров вроде Anthropic, OpenAI и Cursor бывают свои сбои, но не сопоставимые по масштабу с тем, что происходит у GitHub. Прямые конкуренты GitHub — GitLab и Bitbucket — тоже, по всей видимости, испытывают похожий рост нагрузки, однако падают значительно реже.
Напрашивается закономерный вопрос: насколько GitHub сам виноват в своих бедах? Имея за спиной Microsoft, платформа располагает большими ресурсами, чем любой конкурент или стартап, — и тем не менее не предусмотрела роста нагрузки и оказалась слишком большой, чтобы реагировать с проворством стартапа.
Справиться с резким ростом нагрузки — безусловно, сложная задача; именно в таких ситуациях видна разница между средними и выдающимися инженерными командами. GitHub пока не демонстрирует реакции, достойной инженерной организации мирового уровня.
Альтернативы GitHub
Каждый, кто регулярно работает с GitHub, ощущает на себе последствия непрекращающихся сбоев. Как разработчик, можно либо надеяться, что Microsoft в конце концов исправит ситуацию, либо искать альтернативы. Митчелл, как упоминалось выше, сделал выбор в пользу ухода и сейчас решает, куда перенести Ghostty.
Очевидные альтернативы — крупнейшие конкуренты GitHub: GitLab и Bitbucket. Оба предлагают хостинг git-репозиториев и не страдают от тех проблем с доступностью, которые преследуют GitHub.
Вариант самостоятельного развёртывания (self-hosted) тоже доступен: можно поднять собственный git-репозиторий или воспользоваться self-hosted-форжем, например Forgejo — опенсорсной, ориентированной на локальную установку альтернативой GitHub.
Я также предполагаю, что в ближайшее время появятся стартапы, предлагающие возможности хостинга кода уровня GitHub, но с более высокой надёжностью и архитектурой, рассчитанной на тот 30-кратный и более масштаб, который GitHub надеется когда-нибудь поддержать.