Проектирование отказоустойчивых систем с CloudNativePG
Как управлять резервными копиями, восстановлением и пулингом соединений, когда на кону — продакшн
В предыдущей статье я рассказал, что такое CloudNativePG (CNPG) и как запустить кластер PostgreSQL на Kubernetes.
Это была простая часть.
Но в ней осталось за кадром то, что в продакшне важно гораздо больше, — всё, что происходит после запуска кластера:
-
Что делать, если данные повреждены?
-
Как восстановить состояние на конкретный момент времени?
-
Что произойдёт, если к базе одновременно придут 500 соединений?
Запустить PostgreSQL — это не то же самое, что эксплуатировать PostgreSQL.
Эта статья посвящена трём аспектам, которые отличают демонстрационный стенд от настоящей продакшн-системы: резервному копированию, восстановлению и пулингу соединений.
Postgres на Kubernetes: дискуссия, не утихающая в 2026 году
Несмотря на то как далеко продвинулась экосистема, я по-прежнему вижу знакомый паттерн в архитектурных обсуждениях: стоит кому-то предложить запустить Postgres на Kubernetes — и в комнате повисает пауза.
Идею обычно отметают сразу: «слишком рискованно» или «не стоит таких сложностей».
И надо признать, раньше так оно и было. Но сегодня, с такими операторами (Kubernetes Operator), как CloudNativePG:
-
Переключение при отказе (failover) автоматизировано
-
Репликация встроена
-
Резервное копирование и восстановление описываются декларативно
-
Средства наблюдаемости (observability) интегрированы нативно
Настоящий вопрос уже не в том, способен ли Kubernetes запускать Postgres. Вопрос в том, готовы ли команды взять на себя операционную ответственность, которая с этим связана.
Ведь в отличие от управляемых сервисов, здесь ничего не абстрагировано.
Управляемый Postgres против CNPG
Давайте честно оценим компромиссы.

Ключевое различие:
Управляемый Postgres оптимизирован для удобства. CNPG оптимизирован для контроля.
Что изменилось в CNPG v1.28
Если вы смотрели на CNPG несколько версий назад, механизм резервного копирования теперь работает иначе.
Начиная примерно с v1.26 и окончательно в v1.28:
-
Встроенная логика резервного копирования удалена из основного оператора
-
Всё перенесено в систему плагинов (CNPG-I)
Это не мелкое изменение — оно принципиально меняет подход к проектированию резервных копий.
В v1.28:
-
Плагин Barman Cloud — рекомендуемый способ резервного копирования в объектное хранилище
-
Снимки томов (Volume Snapshots) поддерживаются как Kubernetes-нативная альтернатива
-
Полное восстановление и восстановление на момент времени (Point-In-Time Recovery, PITR) — полноценные возможности первого класса
-
Пулинг соединений через PgBouncer встроен
Резервная копия бесполезна, если по ней нельзя восстановиться
Представьте реальную ситуацию. Пятница, послеобеденное время:
-
14:05 — запускается миграция
-
14:12 — вы обнаруживаете, что она удалила данные
Выходные оказались под угрозой. Теперь важен только один вопрос:
Можно ли вернуться к состоянию на 14:04?
В CNPG v1.28 резервные копии явные и плагин-ориентированные. Большинство конфигураций опираются на плагин Barman Cloud:
-
Установка CRD плагина Barman Cloud:
helm repo add cloudnative-pg https://cloudnative-pg.io/charts/helm install barman-cloud-plugin cloudnative-pg/plugin-barman-cloud-
Определение объектного хранилища:
apiVersion: v1
kind: Secret
metadata:
name: my-object-store-secret
data:
ACCESS_KEY_ID: <your-base64-encoded-access-key>
ACCESS_SECRET_KEY: <your-base64-encoded-secret-access-key>apiVersion: barmancloud.cnpg.io/v1
kind: ObjectStore
metadata:
name: my-object-store
spec:
retentionPolicy: "14d"
configuration:
endpointURL: https://s3.amazonaws.com
destinationPath: "s3://my-bucket/postgres/"
s3Credentials:
accessKeyId:
name: my-object-store-secret
key: ACCESS_KEY_ID
secretAccessKey:
name: my-object-store-secret
key: ACCESS_SECRET_KEY
wal:
compression: gzip-
Привязка хранилища к кластеру:
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
...
spec:
plugins:
- enabled: true
name: barman-cloud.cloudnative-pg.io
isWALArchiver: true
parameters:
barmanObjectName: my-object-store # ссылается на ресурс ObjectStore-
Создание резервной копии (в данном случае — по расписанию,
ScheduledBackup):
apiVersion: postgresql.cnpg.io/v1
kind: ScheduledBackup
metadata:
name: my-cluster-backup
spec:
immediate: true
suspend: false
schedule: "0 0 */1 * * *" # Обратите внимание на дополнительное поле секунд
backupOwnerReference: self
cluster:
name: my-cluster # ссылается на ресурс Cluster
target: "primary"
method: plugin
pluginConfiguration:
name: barman-cloud.cloudnative-pg.ioКонфигурация выглядит просто. Но суть не в ней.
Базовая резервная копия (base backup) дотащит вас лишь до определённой точки. Архивирование журнала упреждающей записи (Write-Ahead Log, WAL) — вот что позволяет добраться именно до нужного момента. Без WAL-архивирования вы восстановитесь в прошлое и смиритесь с потерей данных.
Именно здесь чаще всего и возникают проблемы — не в конфигурации, а в допущениях. Резервные копии есть, но восстановление по ним никогда не проверялось.
Снимки томов (VolumeSnapshots) удобны для быстрого отката, но не заменяют восстановление на основе WAL. Они решают вопрос скорости, а не точности.
Главный вывод:
Резервные копии вас не спасут — вас спасёт возможность восстановления.
Восстановление: единственное, что по-настоящему важно
Та же ситуация:
-
Последняя резервная копия — 13:00
-
Сбой — 14:05
Без WAL вы теряете больше часа данных. С WAL — восстанавливаетесь до нескольких секунд до инцидента.
В CNPG восстановление — это тот же PostgreSQL под капотом, но описанный декларативно:
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
...
spec:
bootstrap:
recovery:
source: my-object-store
recoveryTarget:
targetTime: "2026-03-20 14:04:59"Выглядит просто. Но это обманчиво.
Важно другое — работает ли это на самом деле:
-
WAL полон и непрерывен
-
Хранилище согласованно
-
Время восстановления известно заранее
Большинство команд не знают ответа ни на один из этих вопросов — до тех пор, пока он им не понадобится.
Резервные копии — это контрольные точки. WAL — временна́я шкала между ними.
Пулинг соединений: проблема, которую вы не замечаете
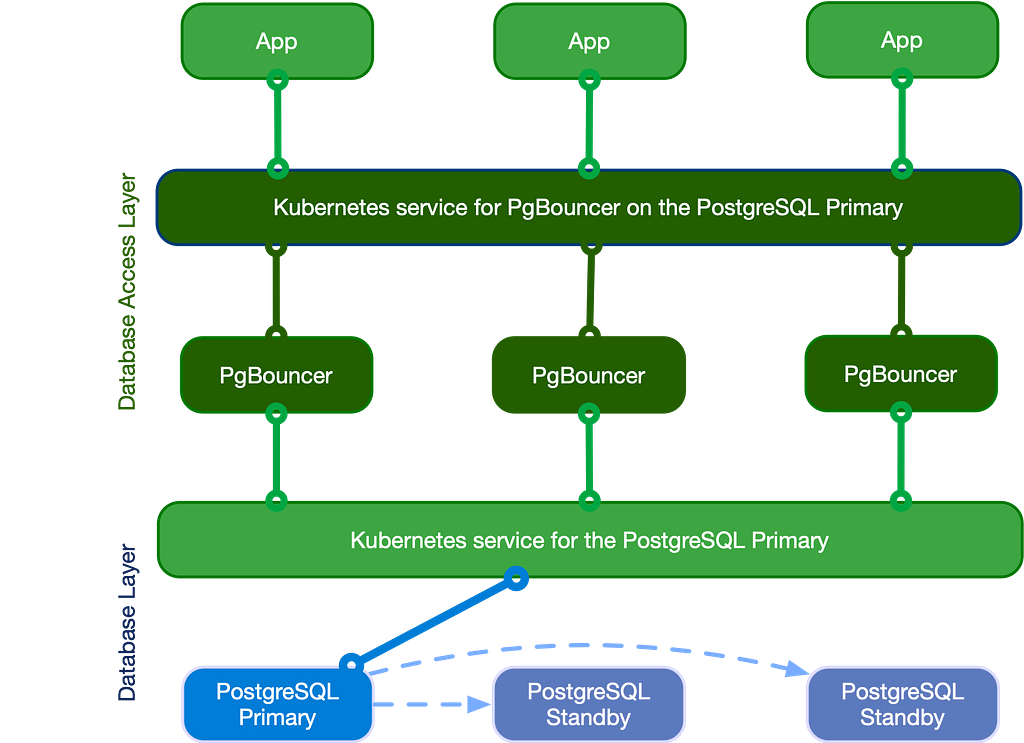
Не все сбои очевидны. Некоторые просто ощущаются как «что-то тормозит».
Kubernetes усугубляет ситуацию. По мере масштабирования приложения вместе с ним растёт и количество соединений. А PostgreSQL плохо справляется с таким ростом.
Ничего не падает — всё просто деградирует.
CNPG решает эту проблему через PgBouncer:
apiVersion: postgresql.cnpg.io/v1
kind: Pooler
spec:
cluster:
name: my-cluster
instances: 2
pgbouncer:
poolMode: sessionPgBouncer встаёт перед базой данных, повторно использует соединения и сглаживает пиковые нагрузки.
Выбор режима пулинга — это компромисс:
-
session— безопаснее, сохраняет состояние сессии. -
transaction— эффективнее, но может ломать операции, зависящие от состояния сессии.
Итог
На практике всё это накатывает одновременно.
Неудачный деплой повреждает данные. В тот же момент резко вырастает трафик. Без возможности восстановления вы теряете данные. Без пулинга соединений база начинает тормозить именно тогда, когда вы пытаетесь всё починить.
Если оба механизма настроены — восстановление происходит быстро, и система остаётся стабильной.
Запустить PostgreSQL на Kubernetes уже не самое сложное. Сложнее — спроектировать систему так, чтобы она выдерживала отказы.
CloudNativePG предоставляет все нужные инструменты, но решения принимать вам. Именно здесь и проявляется разница между работающей системой и по-настоящему отказоустойчивой.
В следующей статье мы рассмотрим, как все эти части складываются в единую картину, — разберём архитектурные паттерны CNPG: маршрутизацию сервисов, поведение при переключении отказа и развёртывание в нескольких зонах доступности: