Архитектура клиент-сервер
Базы данных, как правило, работают по модели клиент-сервер. Сервер базы данных запускается, принимает подключения от клиентов, выполняет запросы и возвращает результаты.
Для бенчмаркинга нужен клиент, который устанавливает соединения, генерирует запросы и снимает замеры. Поскольку обе стороны потребляют ресурсы, а нам важно отдать базе данных всю мощность хостового сервера, бенчмарк обычно запускают на отдельной машине.
Но здесь, как водится, есть подвох: такая схема вносит сетевую задержку между двумя машинами.
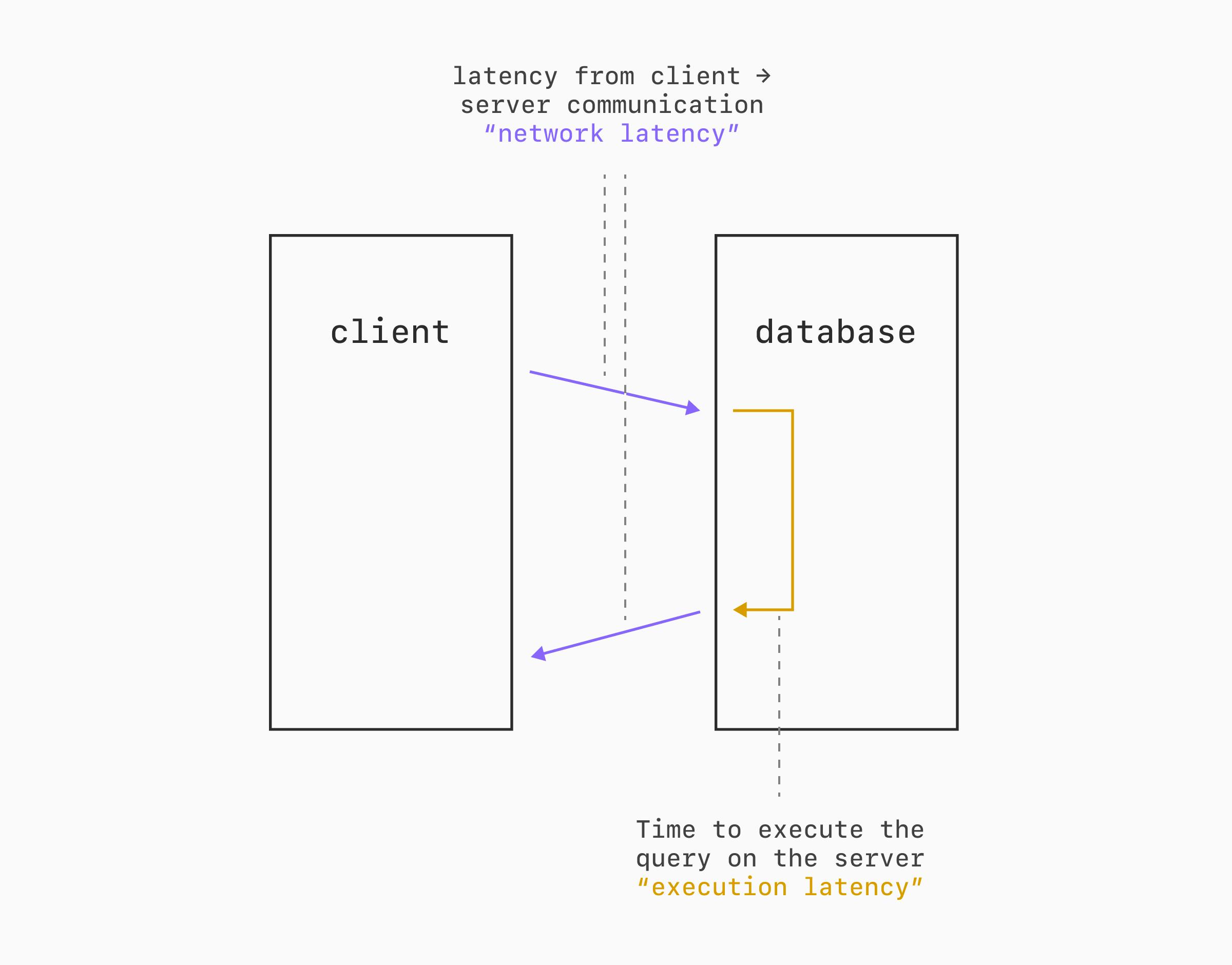
Насколько это искажает результаты, во многом определяется двумя факторами: «расстоянием» между сервером бенчмарка и сервером базы данных (сетевая задержка) и временем выполнения запросов или транзакций на самой базе данных (задержка выполнения).
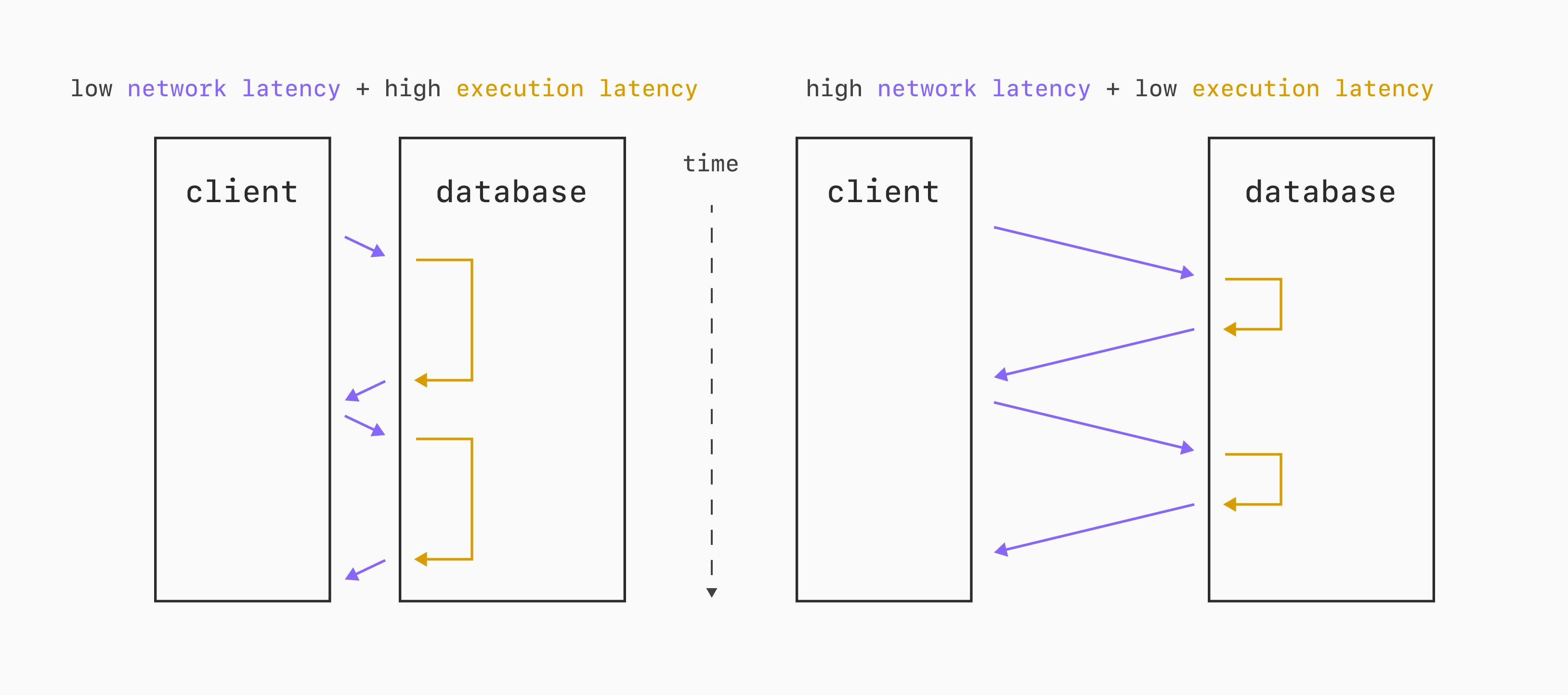
Рассмотрим пример: каждый запрос выполняется на базе данных примерно за 10 мс. Если сетевой round-trip составляет 2,5 мс, через одно соединение можно выполнить около 80 запросов в секунду. А при round-trip в 15 мс однопоточная пропускная способность падает примерно вдвое — до 40 запросов в секунду.
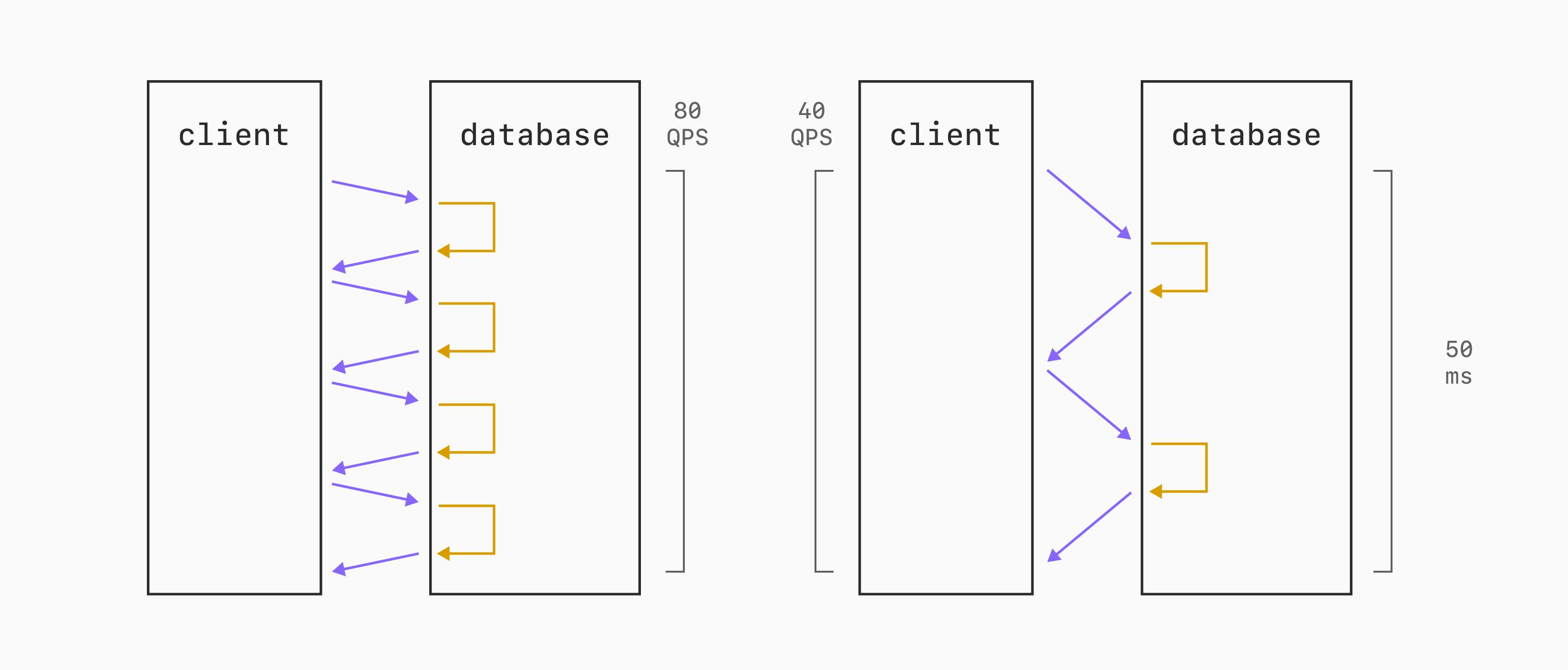
Та же база данных. Тот же бенчмарк-клиент. Разница — только в скорости передачи байт по сети между двумя машинами.
Разброс задержки всегда влияет на латентность замеров. Он может влиять и на пропускную способность. Бенчмарки редко запускают на одном соединении — обычно используют 10, 50 или 100 одновременных подключений, чтобы максимально задействовать параллелизм машины и базы данных. Но если количество соединений фиксировано и не подстраивается динамически под величину round-trip задержки, повышенная латентность может снизить итоговую пропускную способность.
Наконец, стоит убедиться, что клиентский сервер сам не является узким местом. Во время бенчмарка следите за тем, чтобы загрузка CPU и сети на клиентской машине оставалась существенно ниже предельных значений. Нагружать нужно именно сервер базы данных, а не клиент.
Выбор ресурсов
Заставить одну базу данных выглядеть лучше другой несложно — достаточно дать ей больше ресурсов. Postgres на 16-ядерном сервере почти всегда обгонит Postgres на 8-ядерном.
Необходимое условие честного бенчмаркинга — настроить вычислительные ресурсы, хранилище и сеть так, чтобы обеспечить равные условия.
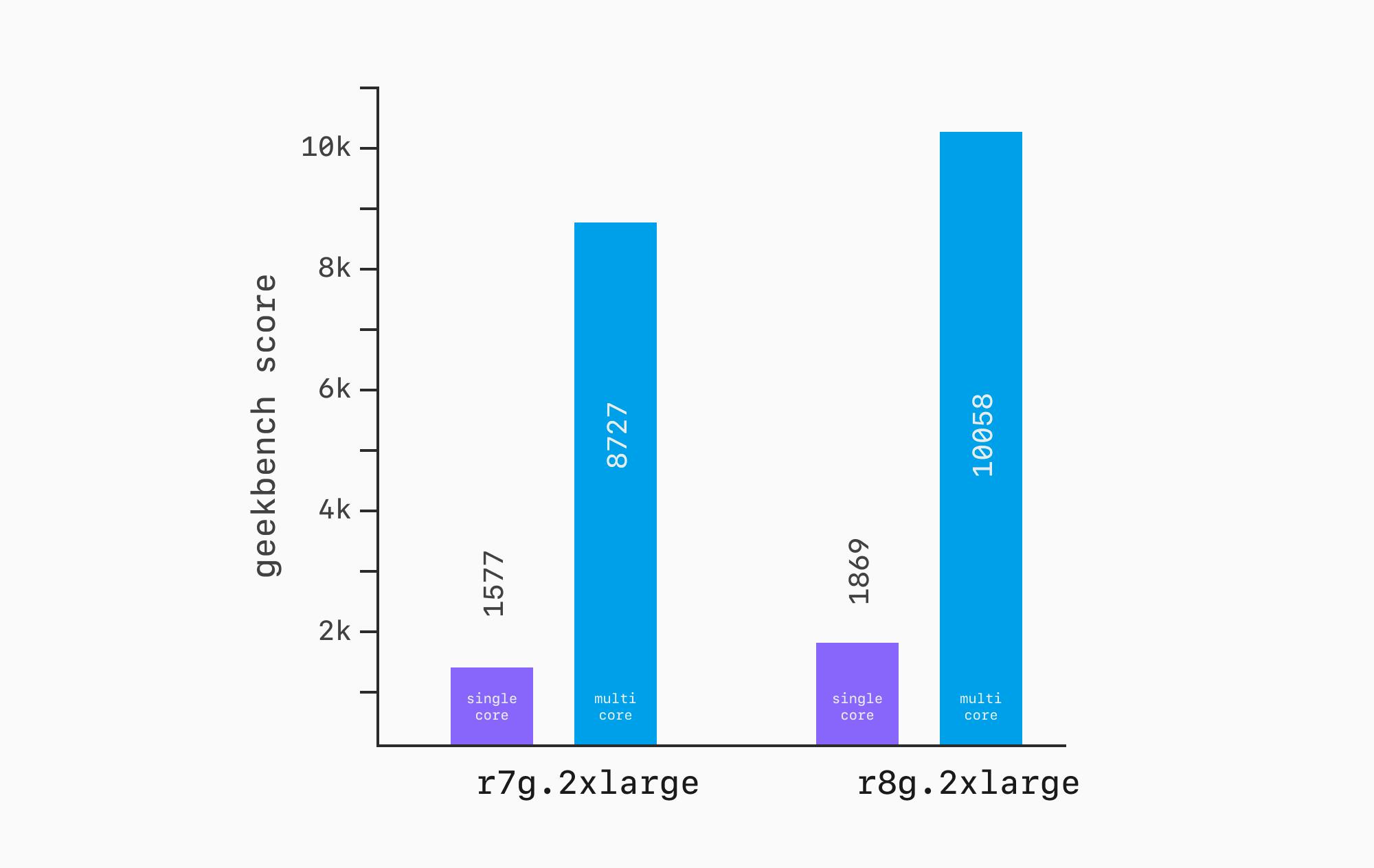
На практике это сложнее, чем звучит, особенно в облаках крупных провайдеров — AWS и GCP. Например, результаты Geekbench для AWS r7g.2xlarge примерно на 15% ниже, чем для r8g.2xlarge. У обоих типов инстансов по 8 vCPU и 64 ГБ RAM. Но переход на одно поколение вперёд даёт прирост CPU около 15%.
Может возникнуть соблазн использовать один и тот же тип инстанса для всего, но и это не панацея. Доступность тех или иных типов инстансов варьируется в зависимости от времени, региона и провайдера базы данных. В ряде случаев добиться полного совпадения попросту невозможно.
В идеале всё нужно запускать на абсолютно одинаковых инстансах. На практике иногда приходится довольствоваться максимально близким совпадением по CPU и RAM и мириться с оставшимися различиями. Тем не менее прикладывать к этому все усилия необходимо. Намеренно выбирать для бенчмарка своего продукта CPU поколения 2025 года и сравнивать его с конкурентом на CPU 2022 года, когда более актуальный вариант легко доступен, — это намеренное введение в заблуждение.
Нагрузка (Workload)
Даже после того как инфраструктура настроена корректно, предстоит решить немало вопросов, связанных с характером нагрузки.
Удобнее всего думать об этом в терминах соотношений трафика:
-
Какая доля запросов обслуживается из RAM, а какая — с диска?
-
Какой процент данных «горячий» (часто запрашиваемый), а какой — «холодный» (запрашиваемый редко)?
-
Каково соотношение операций чтения и записи?
Всё это влияет на производительность, особенно в сочетании с различиями в характеристиках железа.
Запросы к реляционной базе данных почти всегда требуют операций ввода-вывода. Запись данных всегда должна сбрасываться на диск. Чтение данных может обслуживаться из кэша в оперативной памяти или, при промахах кэша, с диска.
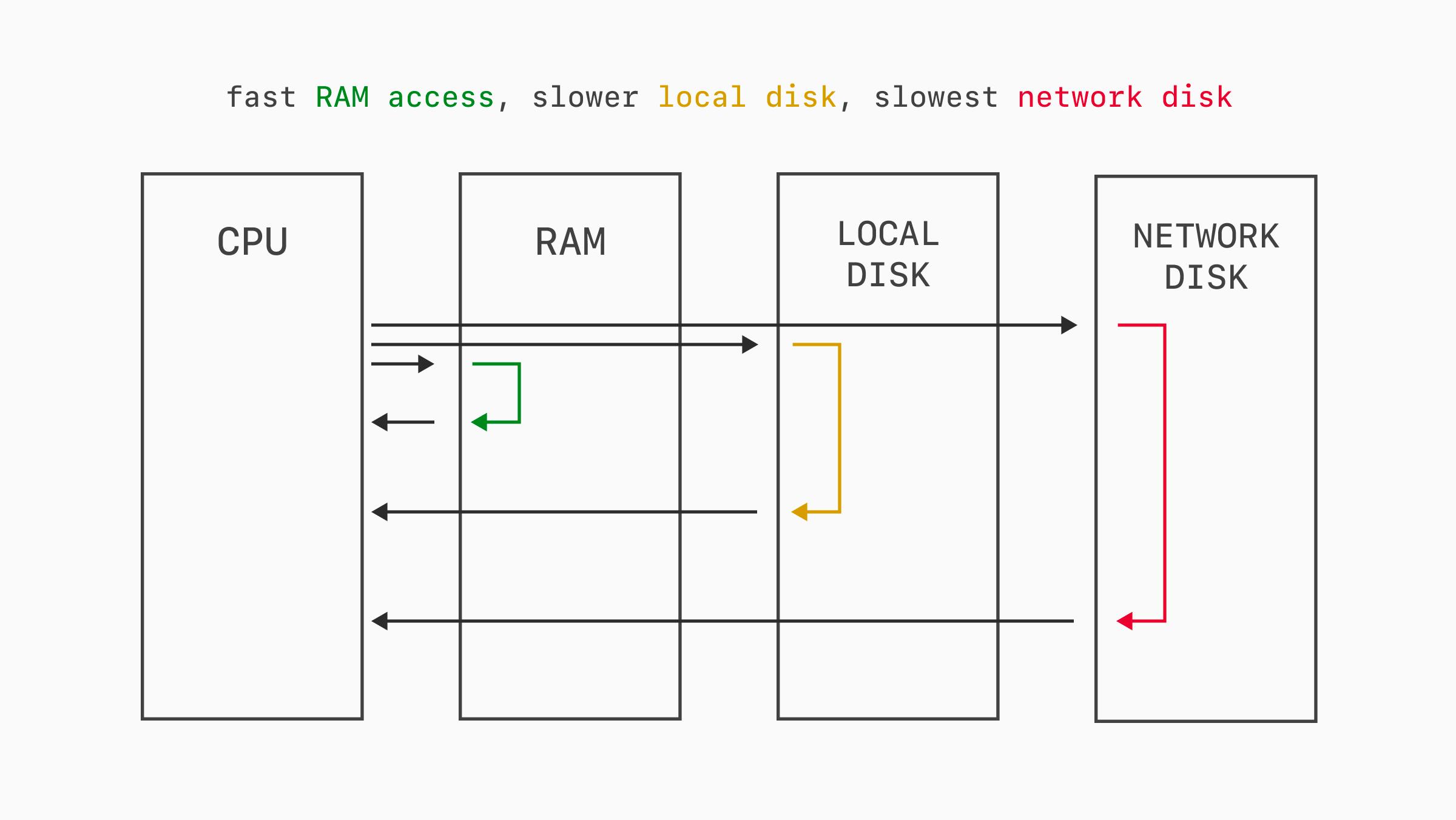
Одни базы данных работают с локальными SSD, другие — с сетевым хранилищем вроде AWS EBS или Google Persistent Disk. Некоторые используют гибридный подход. В любом случае процент операций чтения, попадающих в RAM, а не на диск, напрямую влияет на производительность из-за задержек ввода-вывода.
Рассмотрим, например, бенчмарк sysbench OLTP read-only. Это простой бенчмарк только на чтение, который раз за разом выполняет несколько шаблонных SELECT-запросов. Как это обычно бывает, размер данных задаётся на этапе подготовки. Если запустить этот бенчмарк на сервере с 64 ГБ RAM при объёме данных 32 ГБ, после прогрева весь датасет окажется в оперативной памяти. Тот же бенчмарк с датасетом 320 ГБ создаст значительную нагрузку на ввод-вывод и неизбежно будет работать медленнее.
Это связано с распределением доступа к данным, но не то же самое. Даже при фиксированном объёме данных паттерны обращений могут существенно отличаться. Самые простые примеры — равномерное (uniform) и Ципфово (Zipfian) распределения.
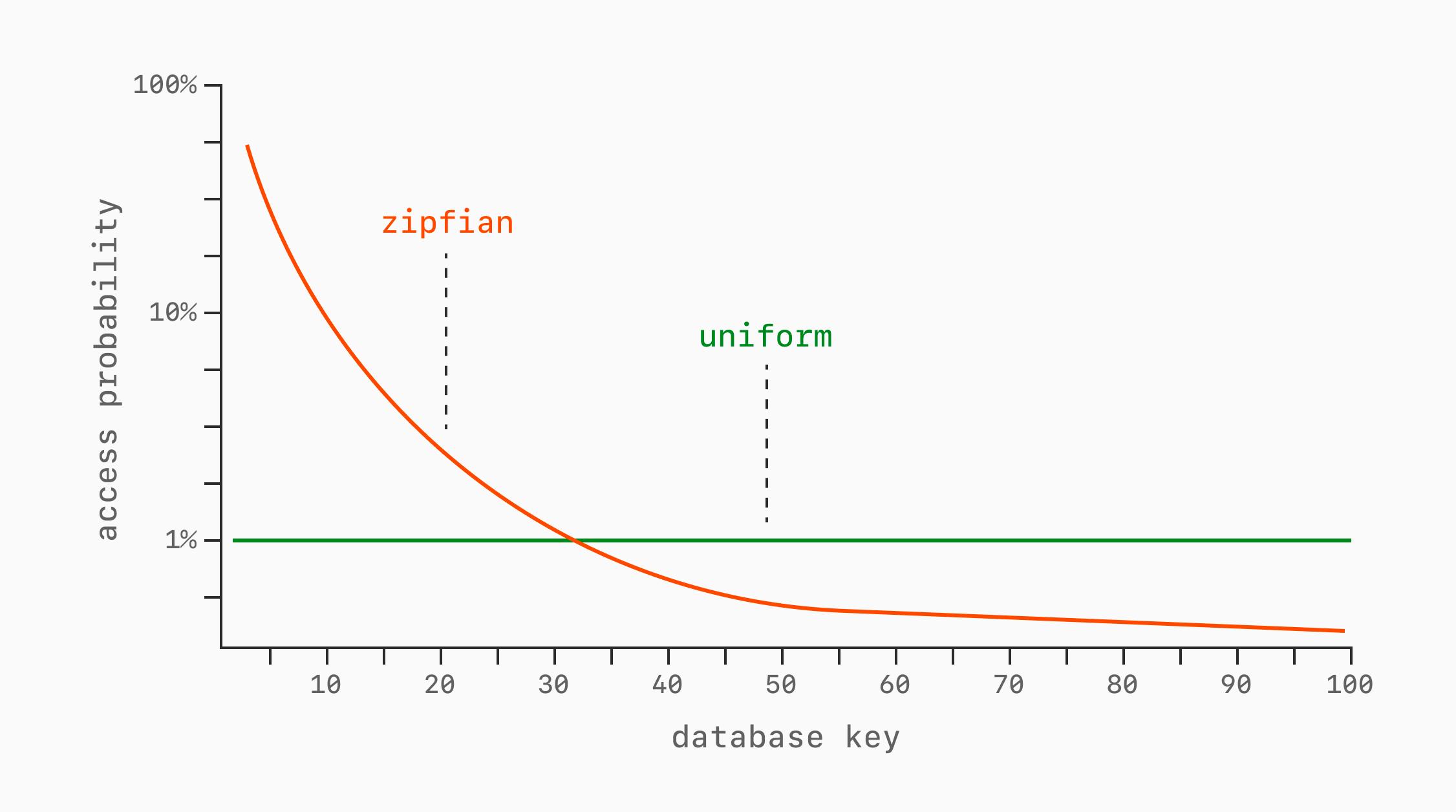
При равномерном распределении каждая строка имеет одинаковую вероятность быть запрошенной. Если строк 100, каждая читается с вероятностью 1% на каждую операцию.
При Ципфовом распределении доступ скошен: k-й по популярности ключ запрашивается примерно с частотой, пропорциональной 1/k. Небольшое число «горячих» строк получает основную долю запросов, а большинство строк обращаются редко.
Это лишь простые модели. Реальные нагрузки часто имеют более сложную форму: недавно вставленные строки могут быть «горячее» старых, один арендатор (tenant) может доминировать в трафике, или небольшой рабочий набор (working set) данных может получать большинство операций чтения в течение какого-то времени.
Паттерн доступа, заложенный в бенчмарке, существенно влияет на производительность, поскольку определяет, как часто нужно обращаться к диску вместо RAM, и насколько интенсивно происходит вытеснение из кэша.
Замкнутый и разомкнутый цикл (Closed and Open Loop)
Существует два вида профилей нагрузки в бенчмарках: разомкнутый цикл (open loop) и замкнутый цикл (closed loop).
В бенчмарке с замкнутым циклом клиент отправляет запрос и ждёт ответа, прежде чем отправить следующий.
while True:
# ждём ответа
response = send_bench_request()
# только потом отправляем следующий
process(response)Это можно делать параллельно через множество соединений, но каждое отдельное соединение выполняет управляемую последовательность запросов. Замкнутый цикл также может скрывать проблему, известную как «координированное упущение» (coordinated omission): когда база данных подвисает, клиент тоже прекращает отправлять новые запросы, поэтому бенчмарк фиксирует только зависший запрос, но не учитывает работу, которая накопилась бы в очереди. Это особенно вводит в заблуждение при оценке хвостовых задержек — ведь именно те запросы, которые оказались «упущены», и ухудшили бы показатели p95/p99 (подробнее о задержках и перцентилях — ниже).
В бенчмарке с разомкнутым циклом, напротив, запросы отправляются с фиксированным темпом, независимо от того, как быстро база данных отвечает.
while True:
# отправляем и не ждём
send_bench_request()
# фиксированный темп
time.sleep(0.1)Темп может оставаться постоянным на протяжении всего бенчмарка или изменяться контролируемым образом:
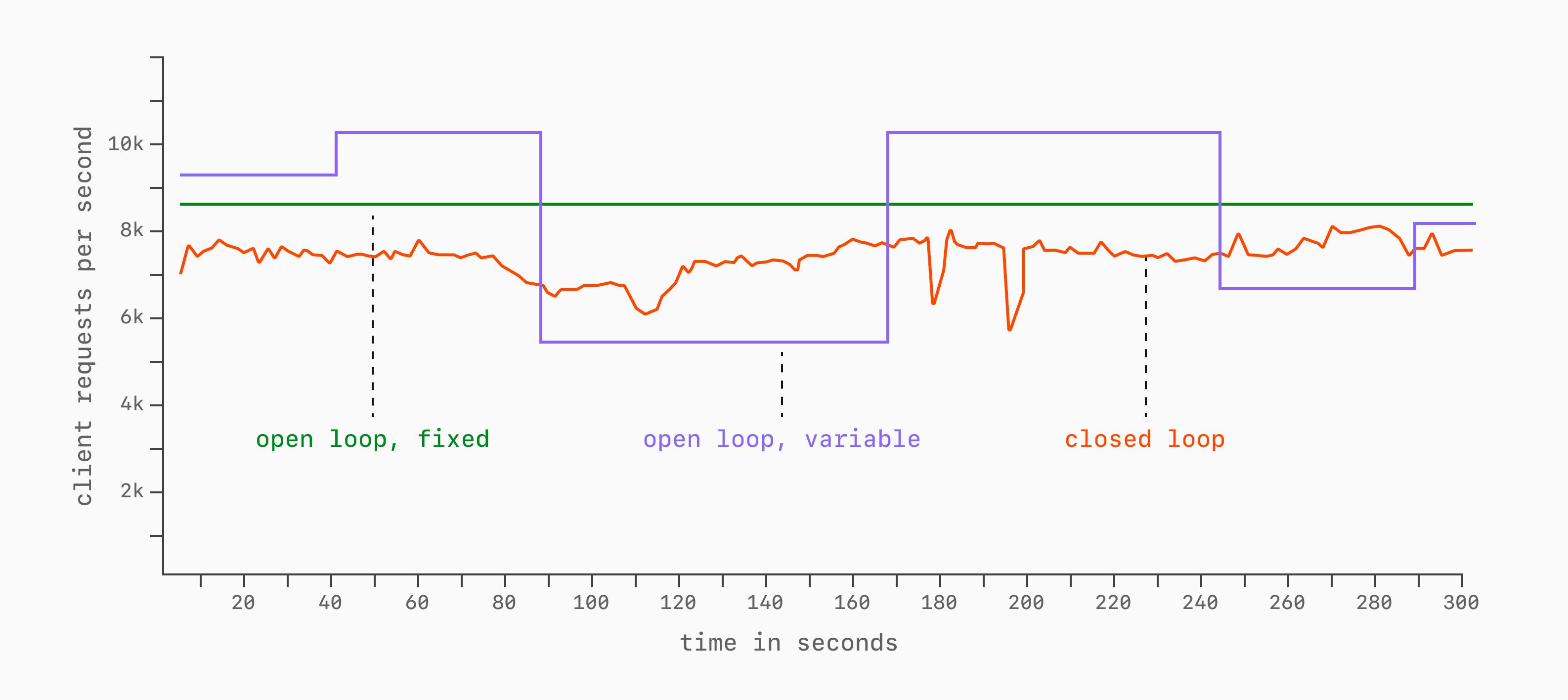
Бенчмарки с разомкнутым циклом, как правило, более реалистичны. В production-системах нагрузка на базу данных определяется темпом, с которым клиенты генерируют запросы, — вне зависимости от того, справляется ли база данных.
Бенчмарки с замкнутым циклом чаще встречаются в академических и сравнительных исследованиях производительности, поскольку обеспечивают более контролируемую среду для сопоставления таких показателей, как QPS при фиксированном уровне параллелизма.
Оба вида полезны, но для разных целей. Важно заранее определить задачу бенчмарка и выбрать тип соответственно.
Что измерять?
В целом при бенчмаркинге измеряют две вещи: пропускную способность (throughput) и задержку (latency). Любой хороший бенчмарк базы данных должен отражать и то и другое.
Пропускная способность (Throughput)
Пропускная способность — это объём работы, выполненной за единицу времени. В базах данных наиболее распространены метрики: запросов в секунду (Queries Per Second, QPS) и транзакций в секунду (Transactions Per Second, TPS). В популярных бенчмарках вроде TPC-C и TPC-H обычно TPS < QPS, поскольку одна транзакция, как правило, содержит несколько запросов. Обе метрики подходят.
Для измерения пропускной способности выберите нагрузку, задайте продолжительность выполнения (например, 5 минут / 300 секунд) и запустите бенчмарк с посекундной выборкой TPS или QPS. По ходу выполнения снимаются замеры того, сколько запросов или транзакций завершается каждую секунду. Результаты отображаются в виде графика с каждой собранной точкой:
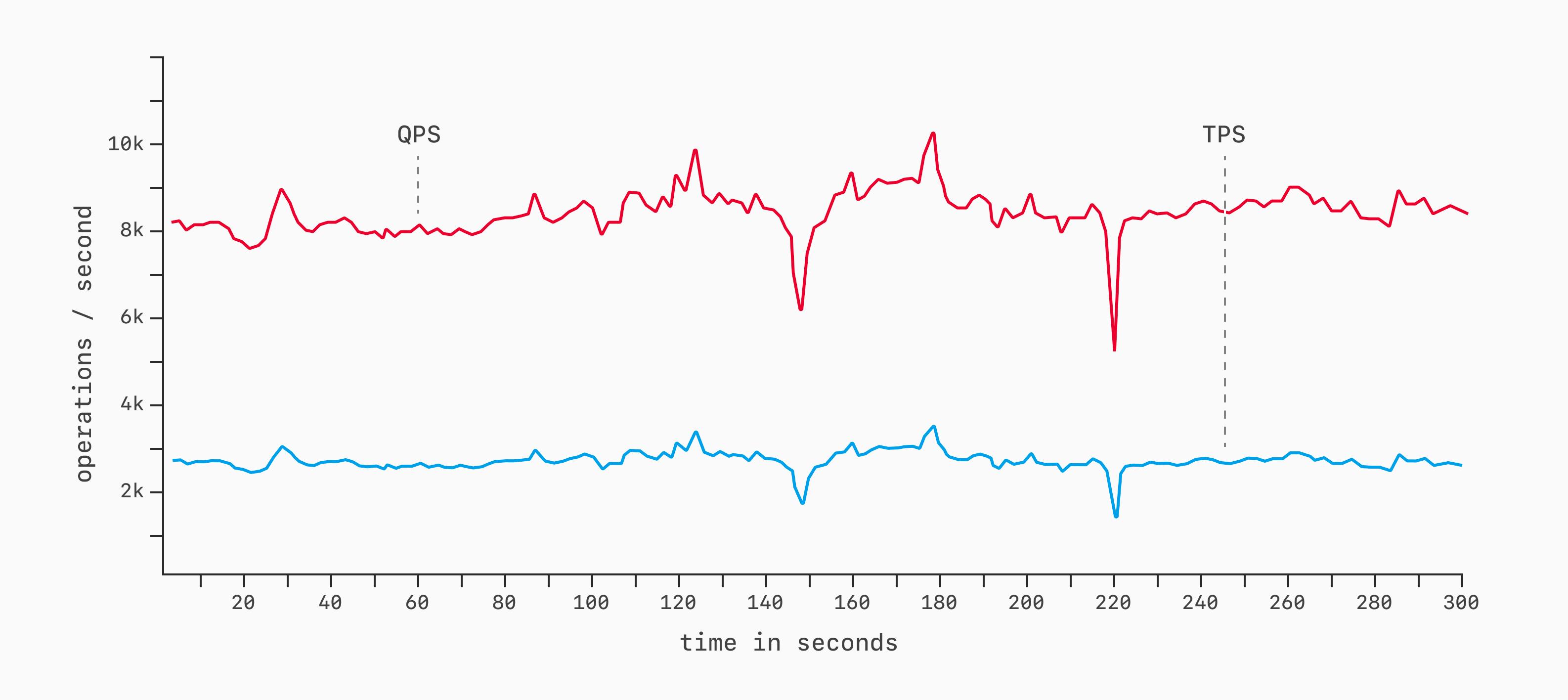
Более компактный способ представления — столбчатая диаграмма с планками погрешностей (error bars).
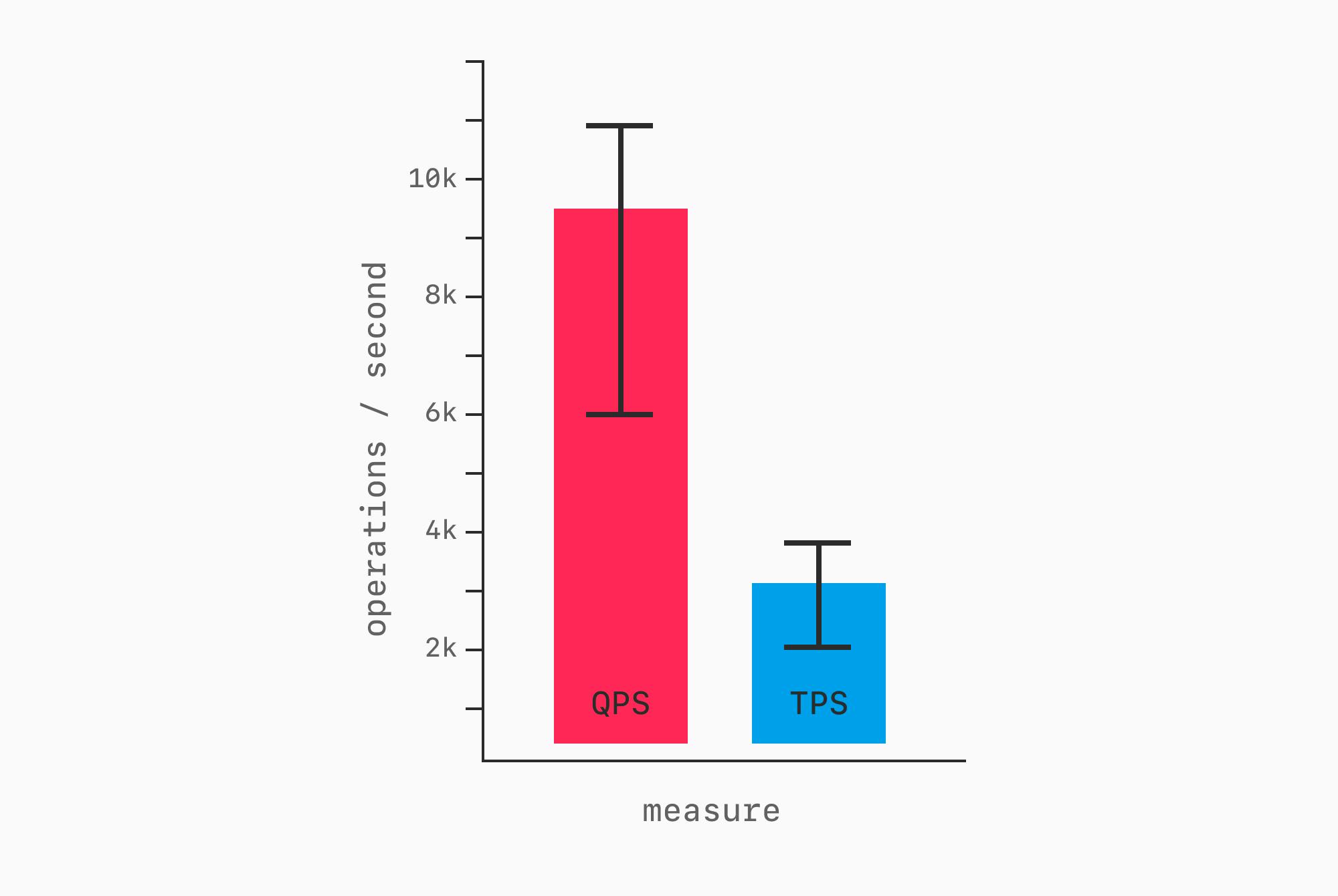
Она передаёт схожую информацию в более сжатой форме, однако полный линейный график предпочтительнее: он лучше показывает неравномерность или скачки производительности на протяжении всего бенчмарка. Подробнее об этом — ниже.
Планки погрешностей — лишь один из способов описать разброс. Коэффициент вариации, межквартильный размах и гистограммы — разные способы взглянуть на одни и те же данные; каждый из них помогает понять, был ли бенчмарк стабильным, зашумлённым или скрывал ли выбросы. Полезно включать их в отчёт или публиковать исходные данные, чтобы читатели могли рассчитать их самостоятельно.
Пропускная способность — лишь половина картины.
Задержка (Latency)
Задержка — это время, которое требуется для выполнения одной операции, запроса или транзакции. Можно смотреть на отдельные задержки («Сколько времени выполнялся этот конкретный SELECT * FROM…?»), но чаще задержки оценивают в совокупности.
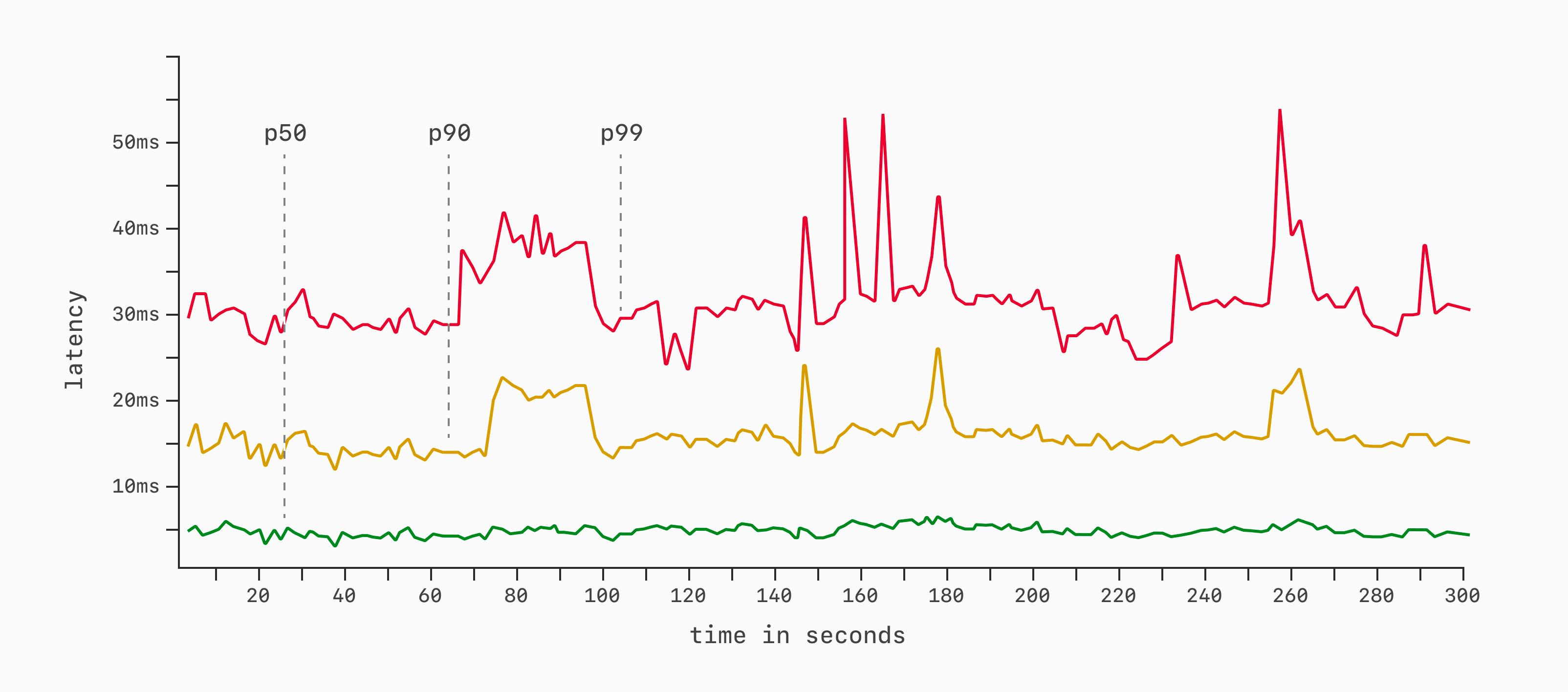
В распределённых системах стандартным языком описания задержек служат перцентили (percentiles) за некоторый промежуток времени (1 секунда, 1 минута и т. д.). Например:
-
p50 — медианная задержка. За данный период половина запросов выполнилась быстрее, половина — медленнее.
-
p90 — 90-й перцентиль. За данный период 9 из 10 запросов выполнились быстрее, 1 из 10 — медленнее.
-
p99 — 99-й перцентиль. За данный период 99 из 100 запросов выполнились быстрее, 1 из 100 — медленнее.
Можно измерять любые перцентили, но перечисленные — наиболее распространённые, наряду с p95 и p99.9. При бенчмаркинге обычно измеряют один или несколько перцентилей в коротких окнах на протяжении всего теста. Например, снимать p50, p90 и p99 раз в секунду в ходе 5-минутного (300-секундного) прогона, а затем строить графики.
В ряде случаев линейные графики избыточны. Как и с пропускной способностью, визуализацию можно сжать до столбчатой диаграммы, показывающей медиану (или среднее) с планками погрешностей.
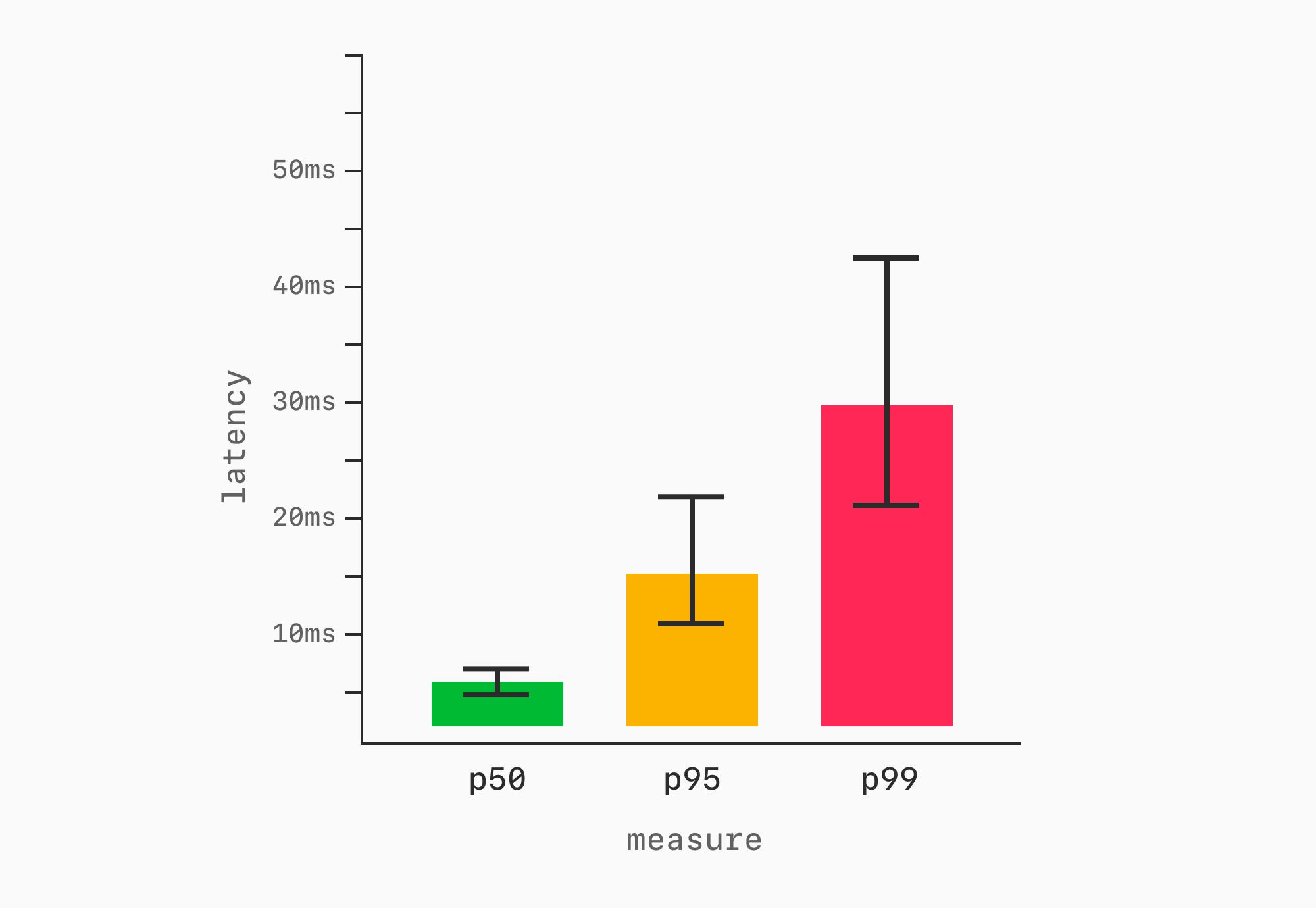
Теперь у нас есть способ показать одновременно сколько работы было выполнено и как быстро выполнялась каждая единица работы.
Прогрев (Warmup)
Мы разобрались с подготовительной частью и знаем, что нужно измерять. Теперь перейдём к практике. Как обеспечить честность при выполнении бенчмарка? Здесь тоже есть немало нюансов.
Один из самых важных — прогрев кэша. Если база данных только что запущена, различные кэши ещё пусты (buffer_cache в Postgres, buffer_pool в MySQL). На их наполнение нужны время и нагрузка: пока они не прогреты, задержка постепенно снижается, а пропускная способность растёт.
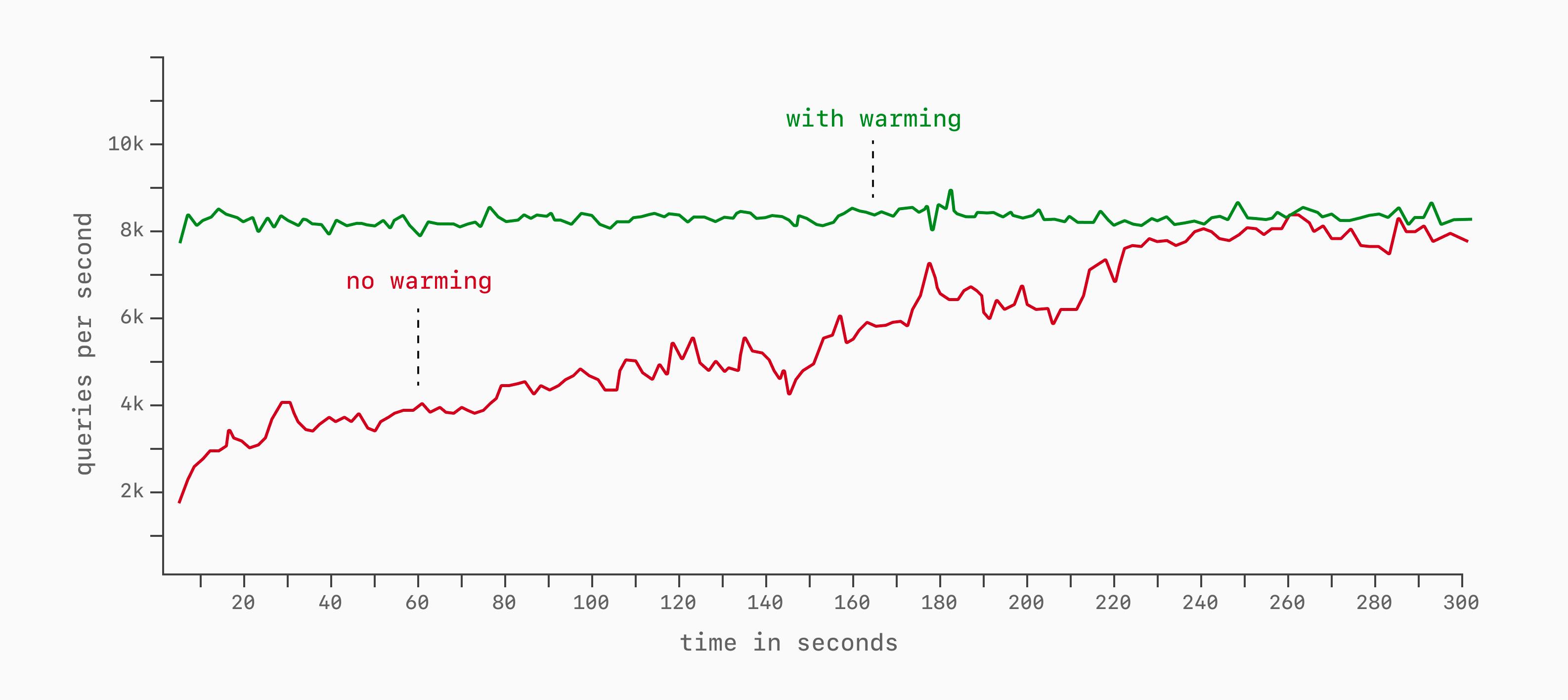
Обычно базу данных запускают без снятия замеров несколько минут, чтобы все кэши успели прогреться, и только после этого начинают измерения. Это исключает влияние холодных кэшей и прочих издержек запуска на итоговые показатели.
Конфигурация (Configuration)
Даже после прогрева существует ряд параметров конфигурации, влияющих на производительность на длительных интервалах. Хороший пример — параметр checkpoint_timeout в Postgres.
Вместе с max_wal_size он определяет, как часто нужно сбрасывать изменения таблиц и индексов на диск (I/O checkpointing). Если задать агрессивные (маленькие) значения, чекпоинт может срабатывать каждую минуту, вызывая регулярные просадки производительности. Если выставить мягкие значения так, чтобы чекпоинт срабатывал раз в десять минут, в результатах 5-минутного бенчмарка это может вообще не проявиться.
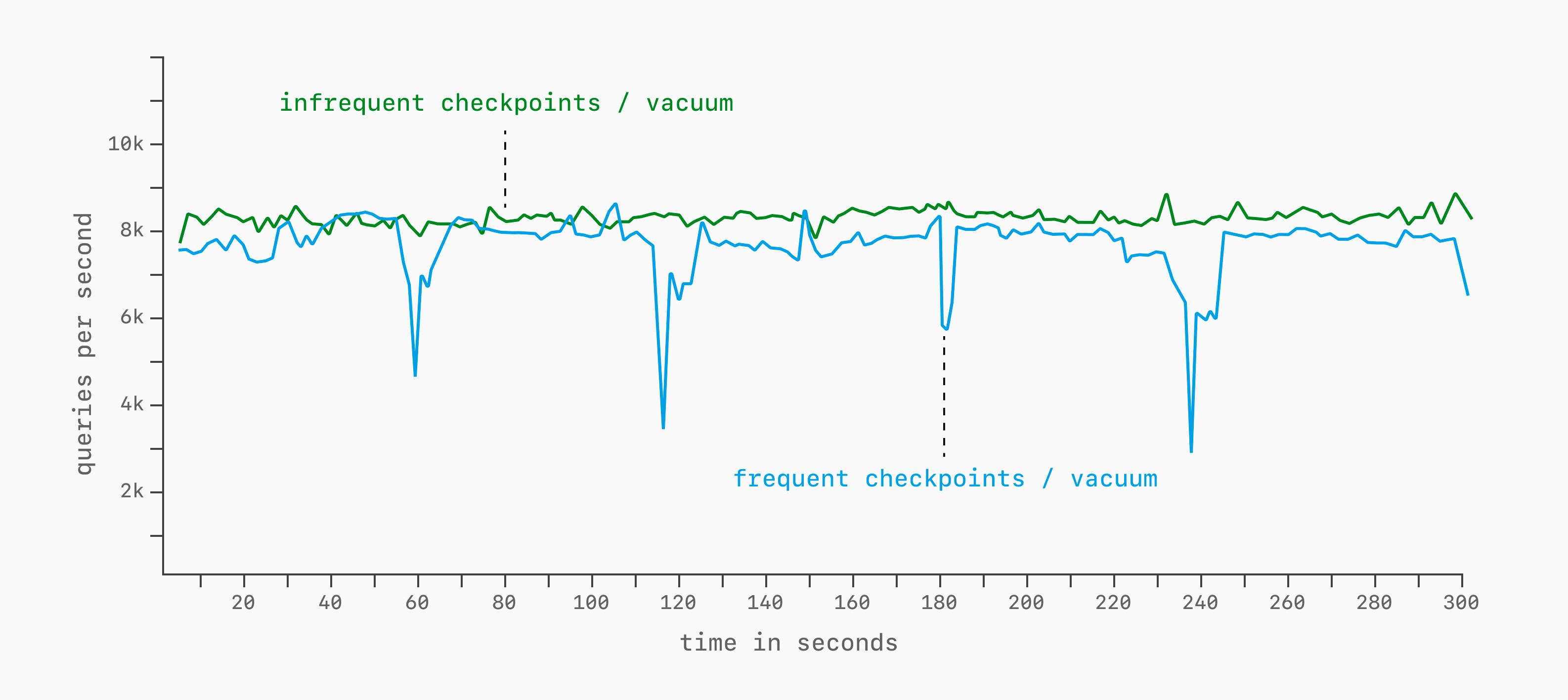
В подобных случаях графики могут выглядеть, как показано выше. Но при увеличении прогона ещё на 10 минут на зелёной линии, скорее всего, проявится заметная просадка.
Фоновые задания, чекпоинтинг, автовакуум и прочие процессы могут влиять на пропускную способность, искажая результаты бенчмарка.
Важно учитывать, как параметры конфигурации базы данных влияют на производительность. Идентичный бенчмарк на одном и том же железе с разными настройками может давать принципиально разные результаты. СУБД предоставляют эти настройки именно для того, чтобы в каждом конкретном случае можно было искать компромисс между производительностью, надёжностью, объёмом данных и потреблением ресурсов. Как правило, лучшим выбором будет либо (а) убедиться, что все параметры конфигурации согласованы, либо (б) в случае предварительно настроенных систем (как у большинства провайдеров «база данных как сервис») оставить заводские настройки по умолчанию.
Непостоянство результатов (In)consistency
Ещё один важный фактор, особенно в облаке, — непостоянство результатов. Даже используя одни и те же инстанс бенчмарка и клиентскую машину, задержки и пропускная способность могут различаться от прогона к прогону. Причина — конкуренция за сетевые ресурсы или «шумные соседи» (noisy neighbors), которые делят с вами то же физическое железо.
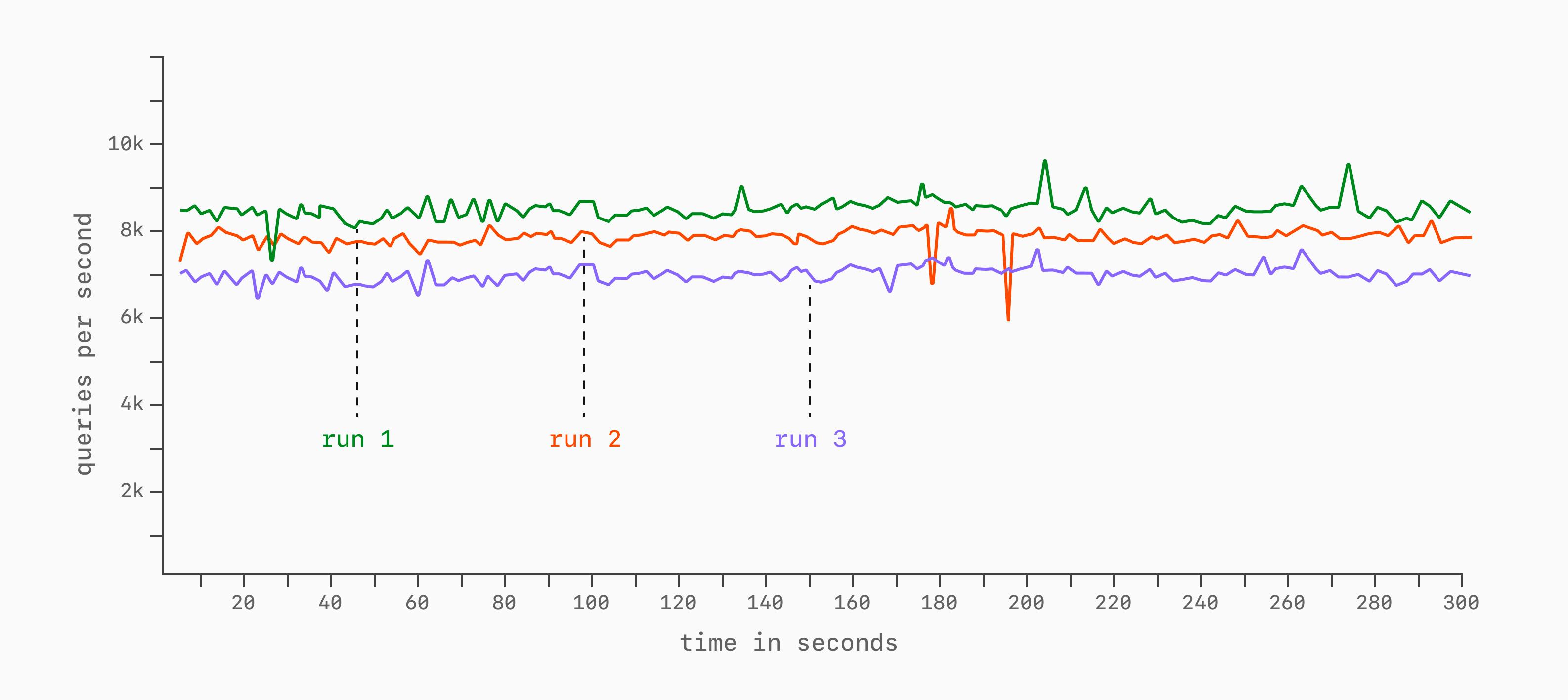
Рекомендуется выполнять несколько прогонов, чтобы оценить стабильность результатов.
Яблоки с яблоками — и с апельсинами
Лучшие бенчмарки — те, которые сравнивают «яблоки с яблоками»: то есть строят основанные на данных сравнения между продуктами с одинаковыми или очень схожими характеристиками и возможностями.
Примеры корректных сравнений:
-
Сравнение 4 различных конфигураций Postgres для выбора оптимальной под конкретную нагрузку.
-
Сравнение 3 облачных MySQL-платформ для определения наиболее производительной.
-
Сравнение MySQL и Postgres на идентичной нагрузке (разные СУБД, но одинаковое назначение).
Иногда люди сравнивают принципиально разные движки баз данных и делают громкие заявления. Например:
-
Аналитические запросы в Apache Pinot работают в 100 раз быстрее, чем в Postgres.
-
Специализированная база данных реального времени даёт QPS в 100 раз выше, чем реляционный Postgres.
-
Задержка SQLite на 80% ниже, чем у MySQL.
Все эти примеры сравнивают базы данных, изначально оптимизированные для разных задач. Заставить одну выглядеть лучше другой несложно — особенно если специально подбирать подходящую нагрузку.
Не делайте так. Сравниваемые технологии и нагрузки должны соответствовать назначению СУБД. Единственное исключение — внутреннее исследование с целью выбрать среди технологий с принципиально разными целями ту, которая лучше всего подходит для конкретной системы.
Документируйте всё
Хорошие бенчмарки должны быть воспроизводимы. Описывайте клиентскую и целевую конфигурации максимально подробно: железо (или тип облачного инстанса), ОС, версии программного обеспечения, флаги сборки, конфигурации, инструмент бенчмаркинга, точную командную строку и т. д. Изучив результаты бенчмарка, инженер должен иметь возможность их воспроизвести.
Ошибки бенчмаркинга
Как видите, качественный бенчмаркинг — дело непростое. Пропуск любого из перечисленных шагов ведёт к смещению результатов. Наиболее распространённые ошибки:
-
Публикация только средних значений без перцентилей, разброса или полного временного ряда.
-
Отсутствие информации о железе, типе инстанса и т. д.
-
Начало измерений до того, как система вышла на установившийся режим.
-
Указание процентного различия без информации об окружающем разбросе.
-
Отказ от проверки, не является ли клиент бенчмарка узким местом.
Последний пункт особенно легко упустить! Если клиентская машина исчерпала CPU или сетевые соединения, график может выглядеть так, будто база данных упёрлась в потолок. На самом деле вы измерили лишь предел самого генератора нагрузки.
Вперёд — бенчмаркить!
Теперь у вас есть базовое понимание бенчмаркинга баз данных.
Представляя результаты, не ограничивайтесь цифрами. Если два прогона существенно отличаются, предложите гипотезу: железо, конфигурация, характер нагрузки, поведение кэша, сетевая задержка или что-то ещё. Читатель не должен самостоятельно выстраивать причинно-следственную цепочку.
Применяйте всё перечисленное в следующем цикле бенчмарков — и вероятность сбиться с курса заметно снизится.