Как мы построили интеллектуальную «финальную задачу», которая превращает 170 000 строк логов в десятистрочный диагноз менее чем за 30 секунд
Сообщение в Slack в три часа ночи, которого никто не ждёт
Если вы работали в платформенной инженерии (platform engineering), DevOps или релизной инженерии, сценарий вам знаком:
@on-call Мой release-пайплайн упал. Не знаю почему. Кто-нибудь может посмотреть логи?
Дальше разворачивается предсказуемый и болезненный ритуал:
-
Вы спрашиваете имя пайплайна, namespace и тенанта.
-
Открываете логи — от 10 000 до 170 000 строк вывода.
-
Скроллите. Ещё скроллите. И ещё.
-
Через 30–60 минут находите: один сервис был временно недоступен.
-
Говорите пользователю: «Просто перезапусти».
Это происходит десятки раз в день в организациях, использующих CI/CD в больших масштабах. И каждый раз это требует участия человека.
Мы решили это исправить.

Масштаб проблемы
В Red Hat мы эксплуатируем Konflux — платформу для сборки, тестирования и выпуска программного обеспечения через конвейеры безопасной цепочки поставок (secure supply chain pipelines). Каждый день там выполняются тысячи пайплайнов — для сборки и выпуска контейнерных образов, операторов и RPM-пакетов.
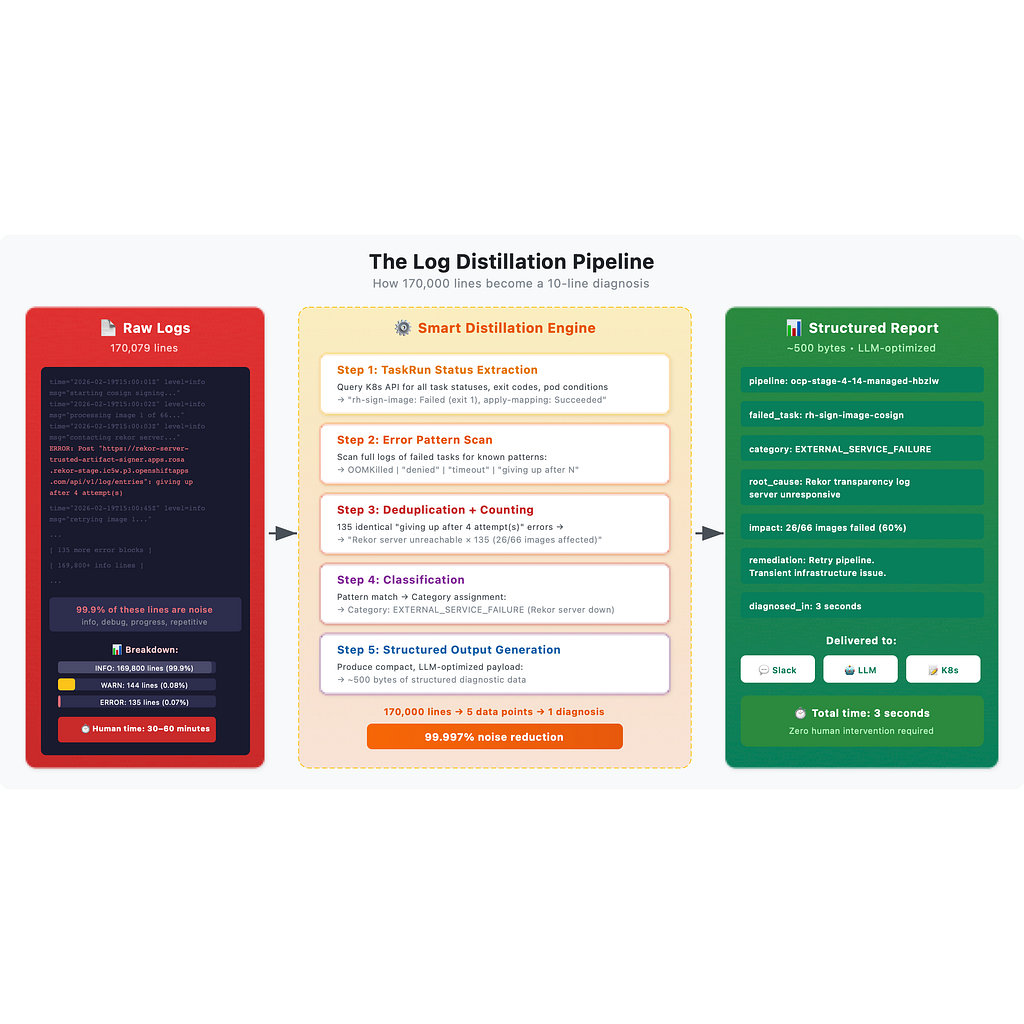
Каждый пайплайн состоит из нескольких Tekton-задач: сборка, сканирование, подпись, верификация, деплой. Когда что-то ломается, логи могут быть огромными. Одна задача подписи образа недавно выдала 171 079 строк вывода. Реальная ошибка? Зарыта на строке 4 684.
Цифры говорят сами за себя:
-
OOM Kill — ~500 строк логов → Человек: 5 мин → Автоматика: 2 сек
-
Ошибка аутентификации — ~2 000 строк → Человек: 15 мин → Автоматика: 2 сек
-
Ошибка подписи образа — 10 000+ строк → Человек: 30–60 мин → Автоматика: 3 сек
-
Полный release-пайплайн — 170 000+ строк → Человек: часы → Автоматика: 5 сек
Умножьте это на количество ежедневных сбоев среди тысяч пользователей — и получите сотни инженерных часов в неделю, потраченных на то, что должно автоматизироваться.
Текущее состояние: почему существующие инструменты не справляются
Вы скажете: «Разве у нас уже нет инструментов для этого?» Давайте разберём:
Агрегация логов (ELK, Splunk, Datadog) — отлично собирают логи, но совершенно не понимают, что именно пошло не так в контексте CI/CD. Они найдут слово «error» в 170 000 строках, но не скажут вам: «Сервер прозрачности Rekor был недоступен, что вызвало 135 ошибок подписи cosign у 18 образов — повторите попытку через 10 минут».
Аналитика CI/CD (GitHub Actions Insights, GitLab Analytics) — отслеживают статистику прохождений/провалов и динамику продолжительности. Это поверхностные метрики: они говорят что сломалось, но не почему.
ИИ-ассистенты для кода (Copilot, CodeGuru) — созданы для исходного кода, а не для логов выполнения пайплайнов. Они не понимают события Kubernetes-подов, зависимости Tekton-задач или процессы аутентификации в container registry.
Пробел очевиден: сегодня ни один инструмент не умеет взять упавший пайплайн, автоматически извлечь нужные сигналы из огромных логов, разобраться в структуре и зависимостях задач пайплайна и выдать конкретный диагноз — без участия человека.
Наш подход: умный анализатор сбоев пайплайна
Мы создали нечто принципиально иное. Основная идея обманчиво проста:
Tekton-задача типа «finally», которая запускается в конце каждого пайплайна — независимо от того, завершился он успехом или провалом, — и автоматически диагностирует произошедшее.
Блок finally в Tekton гарантирует выполнение вне зависимости от результата пайплайна. Это наш крючок. Когда пайплайн завершается, наша задача-анализатор выполняет следующее:
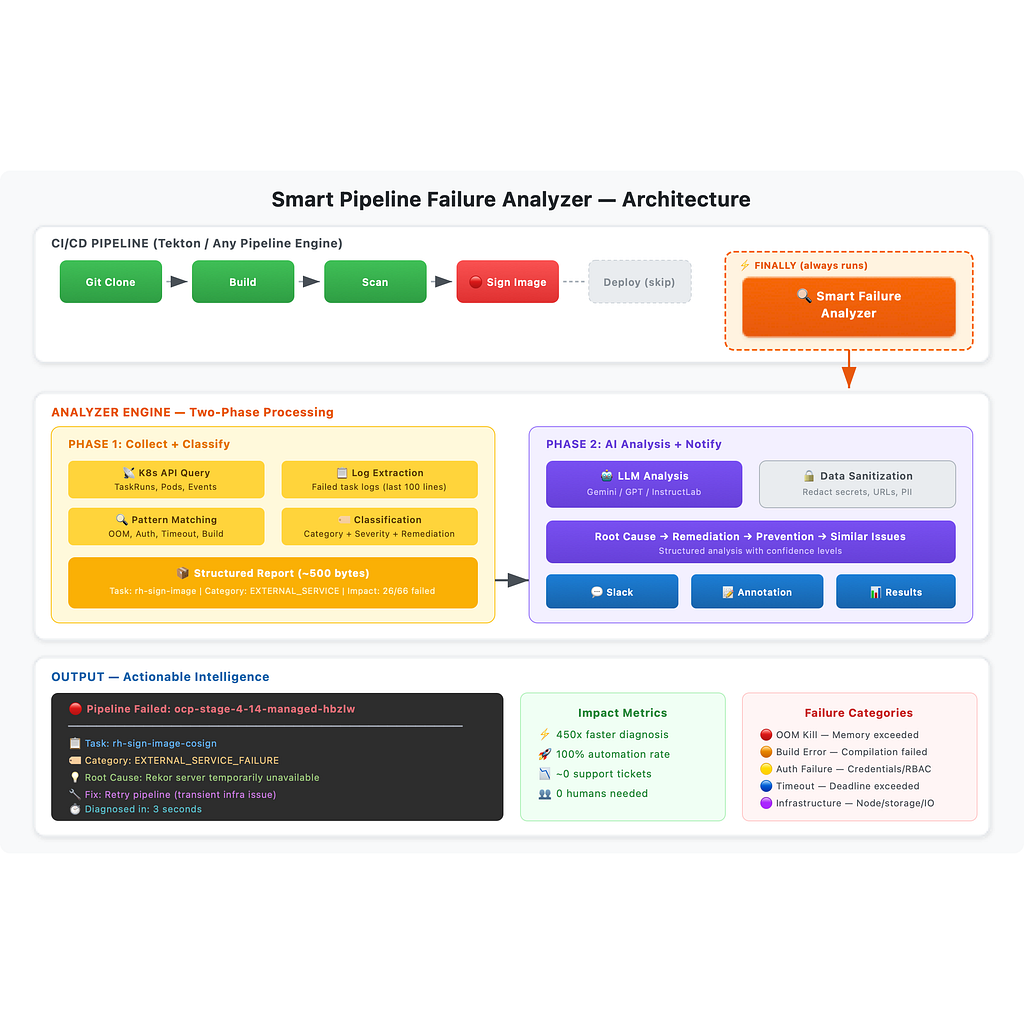
1. Сбор контекста из множества источников
Не только логи. Анализатор обращается к Kubernetes API и собирает:
-
Статусы TaskRun — какие задачи завершились успехом, какие провалились, какие были пропущены
-
Состояния подов (pod conditions) — OOMKilled, ImagePullBackOff, события вытеснения
-
Коды завершения контейнеров (exit codes) — разграничение ошибок приложения и инфраструктурных сбоев
-
Структуру пайплайна — понимание зависимостей задач для выявления каскадных отказов
-
Временну́ю шкалу выполнения — обнаружение таймаутов и аномалий производительности
2. Интеллектуальная дистилляция логов
Это ключевое нововведение. Вместо того чтобы скармливать сырые логи языковой модели или человеку, мы их дистиллируем:
-
Сканирование паттернов ошибок — поиск по полным логам известных сигнатур сбоев
-
Дедупликация — 135 одинаковых ошибок подписи превращаются в одну запись со счётчиком
-
Соотношение успехов и провалов — «40 из 66 образов подписано успешно, 26 — с ошибкой»
-
Определение внешних сервисов — распознавание ситуаций, когда ошибки указывают на зависимости, а не на код пользователя
170 000 строк логов превращаются в структурированный payload ~500 байт, который несёт 100% диагностической ценности.
3. Автоматическая классификация
Анализатор относит каждый сбой к одной из категорий с конкретными рекомендациями:
-
🔴 OOM Kill — контейнер превысил лимит памяти
-
🟠 Ошибка сборки (Build Error) — проблемы компиляции, разрешения зависимостей или Dockerfile
-
🟡 Ошибка аутентификации (Auth Failure) — учётные данные реестра, RBAC или истёкший токен
-
🔵 Таймаут (Timeout) — задача превысила дедлайн или внешний сервис отвечал слишком медленно
-
🟣 Инфраструктура (Infrastructure) — давление на узел (node pressure), дисковый I/O, сетевые проблемы
-
⚪ Внешний сервис (External Service) — недоступная зависимость (Rekor, registry и др.)
Каждая категория сопровождается конкретными шагами по устранению.
4. Настраиваемый ИИ-анализ
Дистиллированные структурированные данные отправляются в настраиваемую языковую модель (LLM) — OpenAI, Google Gemini или self-hosted-модели вроде InstructLab — для углублённого анализа:
-
Определение первопричины с указанием уровня уверенности
-
Шаги по устранению, упорядоченные по вероятности успеха
-
Рекомендации по предотвращению повторяющихся проблем
-
Похожие исторические случаи (при наличии подключённой базы знаний)
5. Мгновенное уведомление
Результаты доставляются команде через Slack (или любой webhook-эндпоинт) в виде красиво отформатированного сообщения — в течение нескольких секунд после завершения пайплайна. Ни один человек не открывает ни единого файла с логами.
Реальный пример
Вот что случилось на прошлой неделе. Пользователь сообщил, что его release-пайплайн упал. Он поделился логами. Задача выполняла подпись образов OpenShift с помощью cosign — стандартная операция, которая подписывает контейнерные образы и записывает подписи в журнал прозрачности Rekor.
Без анализатора:
-
Пользователь открыл логи: 10 002 строки
-
Не смог найти проблему
-
Обратился в канал поддержки
-
Инженер выгрузил и проанализировал логи
-
После нескольких поисков: «Сервер Rekor stage был временно недоступен»
-
Итого: ~45 минут, 2 человека
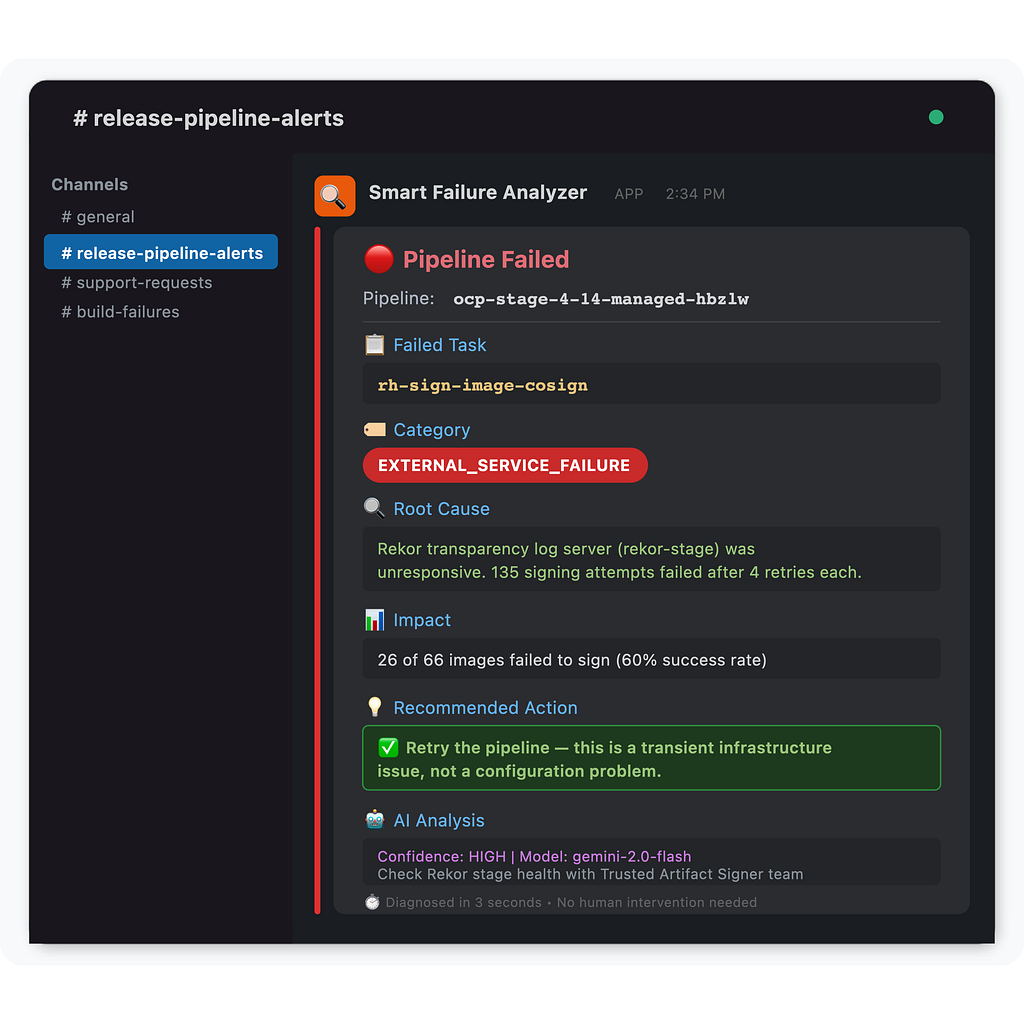
С анализатором:
🔴 Pipeline Failed: ocp-stage-4–14-managed
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
📋 Task: rh-sign-image-cosign
🏷️ Category: EXTERNAL_SERVICE_FAILURE
📊 135 signing errors → 1 root cause
Root Cause: Rekor transparency log server unresponsive
Endpoint: rekor-server-trusted-artifact-signer.apps.rosa…
Impact: 26 of 66 images failed to sign (60% success rate)
💡 Remediation: Retry in 10 minutes. This is a transient
infrastructure issue with the Rekor stage server,
not a pipeline configuration problem.
⏱️ Diagnosed in: 3 secondsИтого: 3 секунды, 0 человек.
Почему это важно за пределами одной команды
Речь идёт не только о наших пайплайнах. Проблема универсальна.
Каждая организация, запускающая CI/CD в масштабе, сталкивается с одним и тем же: сбои случаются, логи огромны, люди становятся узким местом. Используете ли вы Tekton, GitHub Actions, GitLab CI или Jenkins — процесс диагностики одинаково ручной.
Разработанный нами подход принципиально не привязан к конкретному движку пайплайнов. Ключевые инновации — сбор из множества источников, интеллектуальная дистилляция логов, автоматическая классификация и структурированная интеграция с ИИ — применимы к любой пайплайновой системе, которая производит логи и поддерживает запуск задач по завершении.
Аспект безопасности
При интеграции данных CI/CD с ИИ-системами безопасность стоит на первом месте. Нельзя просто отправить сырые логи пайплайна во внешнюю языковую модель — они могут содержать секреты, внутренние URL или конфиденциальные данные.
В нашем подходе есть слой санитизации данных, который:
-
Автоматически обнаруживает и скрывает секреты, токены и учётные данные
-
Заменяет внутренние URL описательными заглушками
-
Применяет настраиваемые политики для определения, какие данные могут покидать кластер
-
Поддерживает self-hosted LLM для максимального контроля над данными (data sovereignty)
Это делает систему безопасной для корпоративных сред, где управление данными — не опция, а обязательное требование.
Цифры
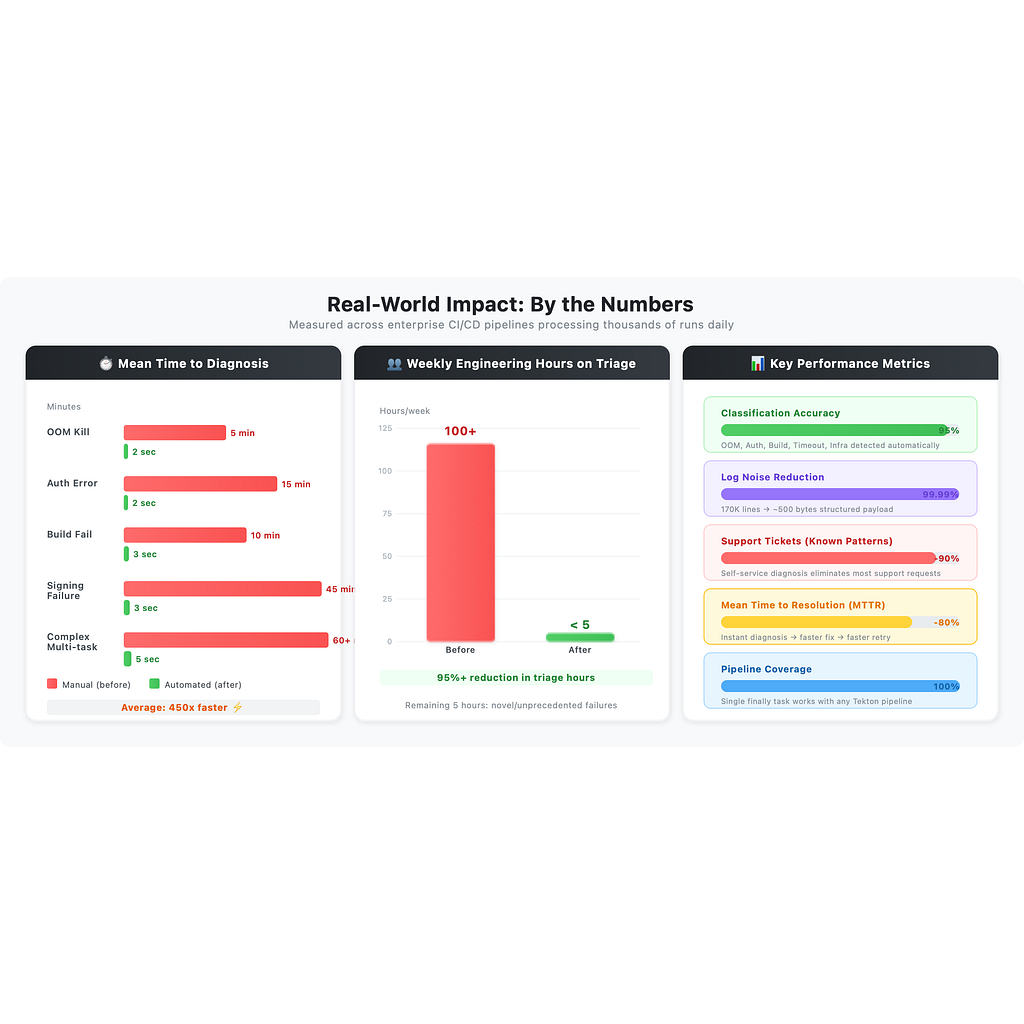
По результатам тестирования и реального использования:
-
Среднее время до диагноза: 30–60 мин → менее 5 сек
-
Количество тикетов в поддержку в день: десятки → почти ноль для известных паттернов
-
Инженерные часы на триаж (в неделю): 100+ → менее 5
-
Строк логов, которые нужно читать человеку: 10 000–170 000 → 0
-
Доля ложных отрицательных результатов (false negative rate): н/д (ручной процесс) → менее 5% (на основе паттернов)
Что дальше
Мы активно развиваем и совершенствуем эту систему. Направления, которые мы изучаем:
-
Обучение на исторических паттернах — формирование базы знаний о решённых сбоях для улучшения классификации со временем
-
Корреляция между пайплайнами — обнаружение ситуаций, когда несколько пайплайнов падают по одной причине (например, при аварии в общей инфраструктуре)
-
Предиктивный анализ — выявление пайплайнов, которые, вероятно, завершатся сбоем, по ранним предупреждающим сигналам
-
Поддержка нескольких движков пайплайнов — расширение за пределы Tekton на другие CI/CD-системы
Попробуйте сами
Основная концепция открыта для обсуждения и совместной работы. Если вы запускаете Tekton-пайплайны и хотите поэкспериментировать с похожим подходом:
-
Начните с finally-задачи — блок
finallyв Tekton — ваш крючок. -
Обращайтесь к Kubernetes API —
kubectl get taskruns -o jsonдаёт вам структурированные данные о статусах. -
Сканируйте логи умно — не просто хвост; ищите паттерны ошибок и считайте их.
-
Структурируйте данные перед отправкой в ИИ — дистиллированные данные дают значительно лучший результат от LLM, чем сырые логи.
-
Автоматизируйте уведомления — Slack webhooks интегрируются элементарно.
Разница между «мой пайплайн упал» и «мой пайплайн упал потому-то, и вот как это исправить» — это разница между реактивной моделью поддержки и проактивной, с самообслуживанием.
Заключение
Диагностика сбоев в CI/CD-пайплайнах слишком долго оставалась задачей, требующей ручного труда. Существующие инструменты отлично собирают данные, но совершенно не умеют их понимать. Объединив интеллектуальную дистилляцию логов, сбор контекста из множества источников, автоматическую классификацию и настраиваемый ИИ-анализ в одну простую «финальную задачу», мы превращаем часы ручной триажировки в секунды автоматической диагностики.
Самое приятное? Это добавление одной-единственной задачи в любой существующий пайплайн. Никаких архитектурных изменений, никакой новой инфраструктуры, никакой миграции. Просто добавьте finally-задачу и позвольте ей делать то, что люди делали вручную — но быстрее, стабильнее и в любом масштабе.
Я Хэппи Бхати (Happy Bhati), работаю в команде релизной инженерии Red Hat и создаю инструменты для конвейеров безопасной цепочки поставок программного обеспечения на платформе Konflux.
Есть мысли по поводу этого подхода? Сталкиваетесь с похожими проблемами? Буду рад услышать вас в комментариях или пообщаться в LinkedIn.
