Симптомы
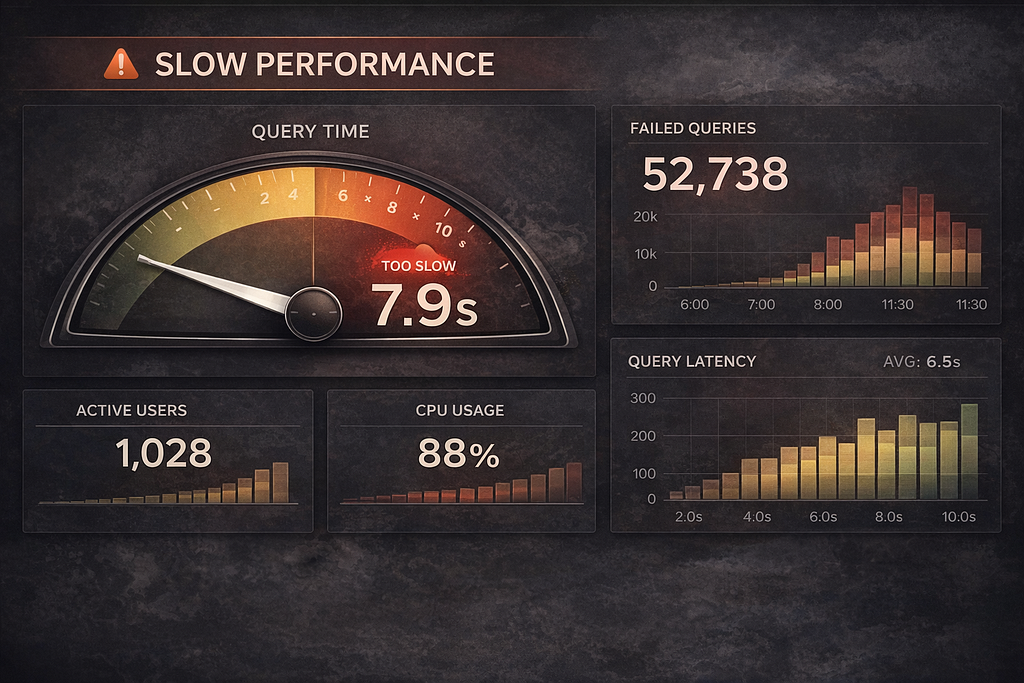
Однажды утром наш экземпляр Grafana для мониторинга начал работать медленно. Дашборды грузились дольше 5 секунд, API-запросы зависали по таймауту, один из трёх подов завис в состоянии CrashLoopBackOff.
Логи говорили сами за себя:
level=error msg="database is locked"
level=error msg="Datasource provisioning error: database is locked"
level=warn msg="cleanup jobs duration" duration_secs=4.4
level=warn msg="saving alert rule state: database is locked"Сотни ошибок database is locked в день. Каждый путь записи в Grafana — провизионирование дашбордов, правила алертов, задачи очистки, управление сессиями — либо завершался с ошибкой, либо уходил на повтор.
Мы запускали Grafana 12.x на Kubernetes, и на первый взгляд всё выглядело разумно: 3 реплики за HorizontalPodAutoscaler, общий постоянный том на Amazon EFS, чтобы все поды могли читать и писать одни и те же данные.
Оказалось, что каждый элемент этой архитектуры был ошибкой.
Что Grafana использует для хранения данных
Вот что удивляет многих, кто разворачивает Grafana в Kubernetes: по умолчанию Grafana использует SQLite. Не PostgreSQL, не MySQL — встроенную однофайловую базу данных, расположенную по пути /var/lib/grafana/grafana.db.
Для одиночного экземпляра это работает отлично. SQLite быстрая, надёжная и не требует обслуживания. Но у неё есть фундаментальное ограничение, критичное в распределённых средах:
«Несколько процессов могут одновременно открыть одну и ту же базу данных. Несколько процессов могут одновременно выполнять SELECT. Но в любой момент времени только один процесс может вносить изменения в базу данных.» — SQLite FAQ
SQLite — это база данных с одним писателем (single-writer database). Для координации записей она использует блокировки на уровне файла: одновременно писать может только один процесс. Когда вы кладёте этот файл на общее сетевое хранилище и направляете на него несколько подов, вы заставляете SQLite координировать запись через сеть. Именно здесь всё и ломается.
Проблема NFS
Amazon EFS — это по сути управляемый NFS (NFSv4.1). Для многих задач он прекрасно подходит: общие конфигурационные файлы, медиафайлы, агрегация логов. Но только не для SQLite.
Документация SQLite прямолинейна:
«SQLite рассчитывает на то, что файловая система реализует блокировки именно так, как это описано в её документации. Однако в некоторых файловых системах встречаются ошибки в логике блокировок, из-за которых те работают не так, как задокументировано. Особенно это характерно для сетевых файловых систем и NFS в частности.» — How To Corrupt An SQLite Database File, раздел 2.1
Справедливости ради: это предупреждение написано прежде всего о NFSv3, у которого блокировки были печально известны своей ненадёжностью (они зависели от отдельного демона lockd, который работал нестабильно). NFSv4 — именно его реализует EFS — исправил проблему корректности. Блокировки работают. Они работают правильно… но медленно.
Каждый захват блокировки — это сетевой round-trip. Каждый fsync — тоже сетевой round-trip. На локальном блочном хранилище (например, EBS) эти операции занимают менее 1 миллисекунды. На EFS — от 10 до 50 миллисекунд.
Звучит не страшно. Но путь записи в SQLite выглядит вот так:
-
Захват блокировки записи → 10–50 мс (сеть)
-
Запись данных → быстро (буфер)
-
fsync журнала → 10–50 мс (сеть)
-
Запись данных в файл базы → быстро (буфер)
-
fsync базы данных → 10–50 мс (сеть)
-
Снятие блокировки записи → 10–50 мс (сеть)
Одна транзакция записи, которая на локальном хранилище занимает менее 2 мс, на NFS растягивается до 40–200 мс. Умножьте это на три пода, одновременно пытающихся писать, — и получите очередь процессов, ожидающих блокировки, завершающихся по таймауту (дефолтный busy timeout SQLite) и пишущих в лог database is locked.
Ловушка HPA
Наша конфигурация делала ситуацию ещё хуже. Для Grafana был настроен HorizontalPodAutoscaler (HPA) с minReplicas: 1 и maxReplicas: 3, ориентированный на 60% использования памяти.
Из-за конкуренции за блокировки горутины накапливались в ожидании доступа к базе данных, и потребление памяти росло. Каждый под использовал около 800 МиБ при лимите в 1 ГиБ. HPA видел 80% утилизации и добросовестно масштабировался до 3 реплик.
Больше реплик означало больше писателей, борющихся за одну блокировку SQLite, а значит — больше памяти, занятой ожидающими горутинами, а значит — HPA масштабировался ещё выше. Идеальная петля обратной связи.
Скрытый штраф Infrequent Access
В Amazon EFS есть функция оптимизации затрат — Infrequent Access (IA, редкий доступ). Файлы, к которым не обращались в течение заданного периода (в нашем случае 7 дней), автоматически переносятся на более дешёвый уровень хранения. Звучит как хорошая экономия.
Но чтение файлов из IA-уровня добавляет дополнительные 100–200 мс задержки при первом обращении — поверх и без того медленных NFS-операций. Когда Grafana перезапускалась и нужно было выполнить миграции SQLite для файла grafana.db, который несколько дней пролежал в холодном IA-уровне, время старта было мучительно долгим.
IA-уровень никак не отражается в метриках Kubernetes или логах Grafana. Его замечают только как загадочную дополнительную медлительность, которая то появляется, то исчезает в зависимости от паттернов доступа.
Решение: одна реплика и локальное хранилище
Решение оказалось до неловкого простым: перейти с EFS (NFS, ReadWriteMany) на EBS (блочное хранилище, ReadWriteOnce) и запустить одну реплику.
Потребление памяти упало на 60% — не потому, что мы изменили какую-либо конфигурацию ресурсов, а просто потому, что горутин, накапливавшихся в ожидании блокировки, больше не существует.
Правильный способ обеспечить высокую доступность
Переход на одну реплику с блочным хранилищем решает непосредственную проблему производительности, но жертвует высокой доступностью (HA). Для многих команд, особенно тех, кто использует Grafana как вспомогательный инструмент наблюдаемости, это приемлемый компромисс — быстрое восстановление (около 7 секунд старта) делает кратковременную недоступность несущественной.
Но если организации требуется настоящий HA Grafana без простоев, ответ — не общее NFS-хранилище. Правильный подход таков:
Используйте полноценную клиент-серверную СУБД
Для мультиинстансных развёртываний Grafana официально поддерживает PostgreSQL и MySQL.
При использовании внешней базы данных:
-
Несколько реплик Grafana могут читать и писать одновременно без конкуренции за блокировки
-
База данных сама управляет репликацией и переключением при сбое (например, RDS Multi-AZ)
-
Общая файловая система не нужна — каждому поду достаточно локального или временного хранилища для кэшей
-
Горизонтальное масштабирование действительно работает
Нюанс NFSv4
Распространённый контраргумент звучит так: «Но мы используем NFSv4, а он исправил проблемы с блокировками NFS».
Это наполовину верно. NFSv4 действительно исправил корректность блокировок NFS. В NFSv3 рекомендательная блокировка (advisory locking) опиралась на отдельный демон lockd, снискавший дурную славу из-за своей ненадёжности — блокировки могли молча давать сбой, что приводило к реальной порче базы данных. В NFSv4 обязательная блокировка байтовых диапазонов (mandatory byte-range locking) встроена прямо в протокол. Блокировки работают. Они работают корректно.
Но они работают через сеть. А для SQLite, которая синхронно вызывает fcntl() и fsync() при каждой транзакции, «корректно, но медленно» лишь ненамного лучше, чем «сломано». Порчи данных вы не получите. Зато получите таймауты.
Это расследование началось с «Grafana работает медленно» и завершилось перепроектированием хранилища на 8 кластерах, очисткой брошенных ресурсов, накопившихся за годы, и переписыванием скриптов резервного копирования. Порой самые незначительные симптомы обнажают самые глубокие проблемы.