Применение паттернов Kubernetes к нагрузкам с LLM
Как уже знакомые паттерны переносятся на LLM — и где у них появляются важные нюансы.
Несколько лет назад мы с Роландом Хуссом написали книгу Kubernetes Patterns — каталог повторно используемых решений для построения облачно-нативных (cloud-native) приложений на Kubernetes. Книга охватывает шесть категорий паттернов: фундаментальные, поведенческие, структурные, конфигурационные, безопасности и продвинутые — от проб работоспособности и init-контейнеров до контроллеров, операторов и эластичного масштабирования. Недавно Роланд вместе с Даниэле Зонкой написали новую книгу Generative AI on Kubernetes, посвящённую операционной стороне запуска больших языковых моделей (LLM) на Kubernetes. Я выступал рецензентом этой книги, и чем дальше я её читал, тем отчётливее узнавал паттерны из нашей оригинальной работы — только применённые к принципиально иному классу нагрузок. Deployment, StatefulSet, Init Container, DaemonSet — всё это было на месте. Просто с другим порядком цифр.
Ниже — краткий обзор того, как паттерны Kubernetes применяются к нагрузкам с LLM. Подробнее мы с Роландом разберём это на нашем предстоящем докладе на KubeCon + CloudNativeCon Europe 2026 в Амстердаме.
Тот же Kubernetes, другая нагрузка
Типичное облачно-нативное приложение на Kubernetes строится по хорошо известной схеме.
-
Ingress направляет HTTP-трафик к stateless-подам приложения, управляемым Deployment.
-
Init-контейнер выполняет миграции базы данных до старта приложения.
-
PostgreSQL работает как StatefulSet с постоянным хранилищем.
-
CronJob генерирует отчёты по расписанию.
-
Слой DaemonSet — например, Prometheus Node Exporter и Fluentd — обеспечивает мониторинг и сбор логов.
Итого шесть паттернов Kubernetes в действии: Controller, Stateless Service, Init Container, Stateful Service, Batch Job, Daemon Service.
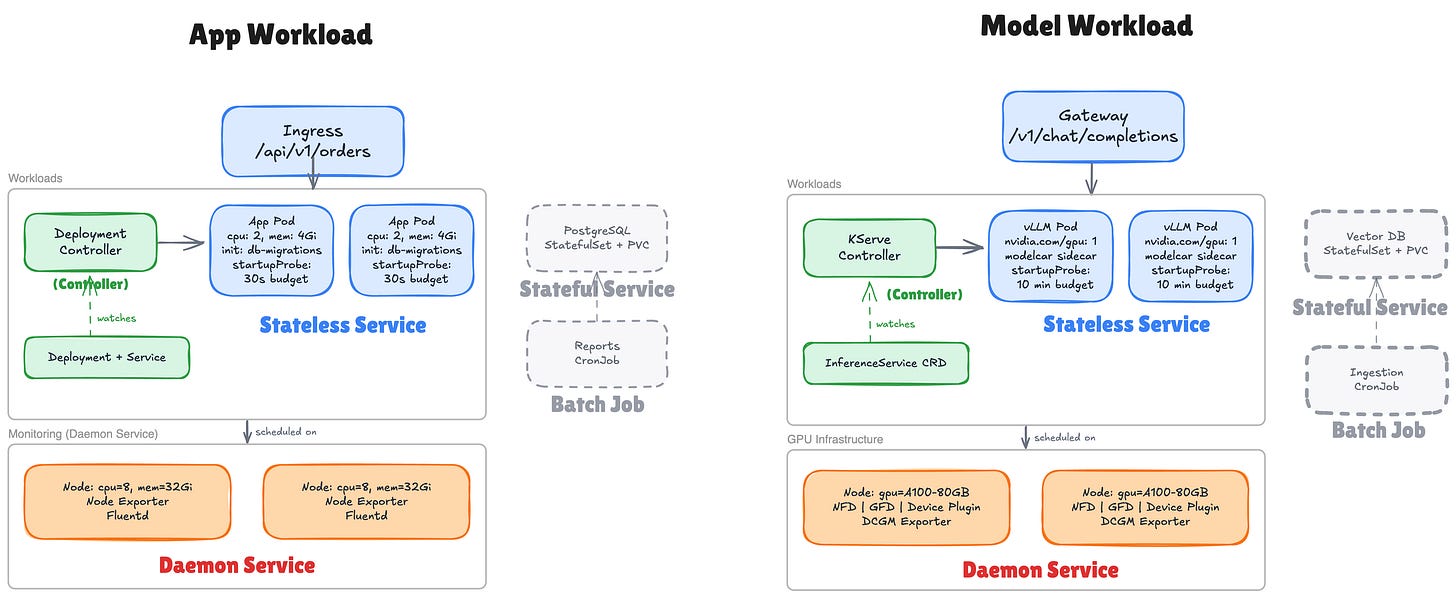
Нагрузка с LLM использует те же паттерны, но представляет собой принципиально иной тип рабочей нагрузки.
Модель — это не бинарный файл приложения. Это десятки или сотни гигабайт выученных параметров, данные только для чтения, которые необходимо загрузить в память GPU, прежде чем сервер сможет обработать хотя бы один запрос. Llama 70B от Meta весит около 140 ГБ в полной точности (FP16) или 35–40 ГБ при 4-битном квантовании. Загрузка занимает минуты, а не секунды.
Модели требуется специальное железо: узел с нужным GPU, достаточный объём VRAM (Video RAM — память на GPU, где хранятся веса модели и промежуточные вычисления), а иногда и конкретная топология GPU-интерконнекта.
Инициализация тоже выглядит иначе. В традиционном приложении init-контейнер скачивает конфигурационный файл или выполняет миграцию — несколько мегабайт, дело секунд. В стеке с LLM аналогичный шаг загружает десятки или сотни гигабайт весов модели. После того как веса на месте, сервер модели (vLLM, TGI) проходит многофазный запуск: загружает веса в VRAM, компилирует CUDA-графы и предварительно выделяет KV-кэш (область памяти, где модель хранит вычисленные состояния механизма внимания, чтобы не пересчитывать их для каждого нового токена). Всё это занимает минуты. Ваш startup probe должен иметь failureThreshold: 60 при periodSeconds: 10 — то есть бюджет ожидания в 10 минут.
Профиль запросов тоже отличается. В традиционном веб-сервисе запросы имеют примерно одинаковую стоимость, и балансировка по round-robin работает. LLM-инференс нарушает это допущение: запрос на 10 токенов выполняется за 200 мс, а запрос на 4 000 токенов занимает GPU на 30 секунд. При этом оба приходят как идентичные запросы POST /v1/chat/completions. Round-robin создаёт горячие точки.
Сигналы для масштабирования тоже перестают работать. Стандартный HPA по CPU плохо подходит для GPU-инференса. Нужно масштабирование по метрикам, специфичным для LLM: глубина очереди токенов (vllm:num_requests_waiting), время до первого токена (time-to-first-token), утилизация KV-кэша.
Масштабирование до нуля (scale-to-zero) практически нереализуемо, когда загрузка модели занимает пять минут.
Меняется и инфраструктурный слой. Вместо Node Exporter и Fluentd теперь запускаются: NFD (Node Feature Discovery) для маркировки железа, GFD (GPU Feature Discovery) для добавления меток модели GPU и объёма VRAM, NVIDIA device plugin для предоставления nvidia.com/gpu как планируемого ресурса и DCGM exporter (Data Center GPU Manager) для передачи GPU-метрик в Prometheus. Это ваш новый стек DaemonSet, формирующий GPU-инфраструктурный слой.
Такие проекты, как KServe (инкубируется в CNCF), решают эти задачи, применяя паттерн Controller к обслуживанию моделей. Вы описываете InferenceService CRD, декларируете модель, среду выполнения и политику масштабирования — а KServe выполняет согласование: создаёт Deployment, Service, инициализатор хранилища, настраивает startup-пробы и планирование на GPU.
Несмотря на всё это, фундамент остаётся прежним. Controller, Stateless Service, Init Container, Stateful Service, Batch Job, Daemon Service — все паттерны на месте. Параметры изменились, но паттерны выдержали.
Что остаётся неизменным в GenAI на Kubernetes
Многие паттерны Kubernetes применяются к нагрузкам с LLM без принципиальных изменений. Паттерн работает как есть — его просто нацеливают на другую нагрузку.
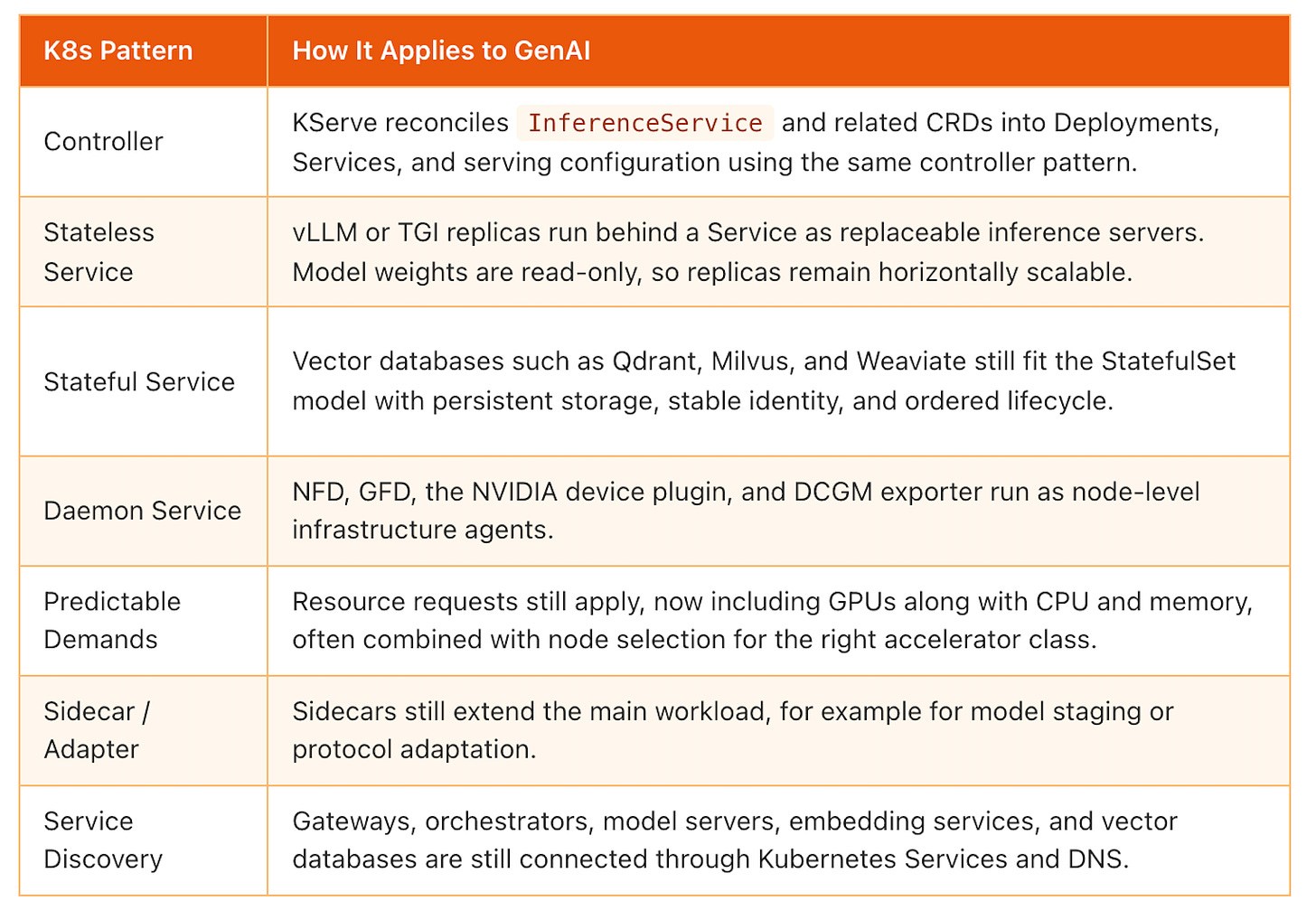
Это прямые соответствия. Примитив Kubernetes остаётся тем же, но нагрузка за ним меняется: веб-приложения и базы данных уступают место серверам моделей, векторным базам данных и GPU-инфраструктуре.
Что меняется в GenAI на Kubernetes
Эти паттерны по-прежнему применимы к GenAI, но кое-что принципиальное в их работе меняется. Скелет паттерна остаётся прежним, однако параметры, масштаб или семантика выходят за рамки изначального замысла.
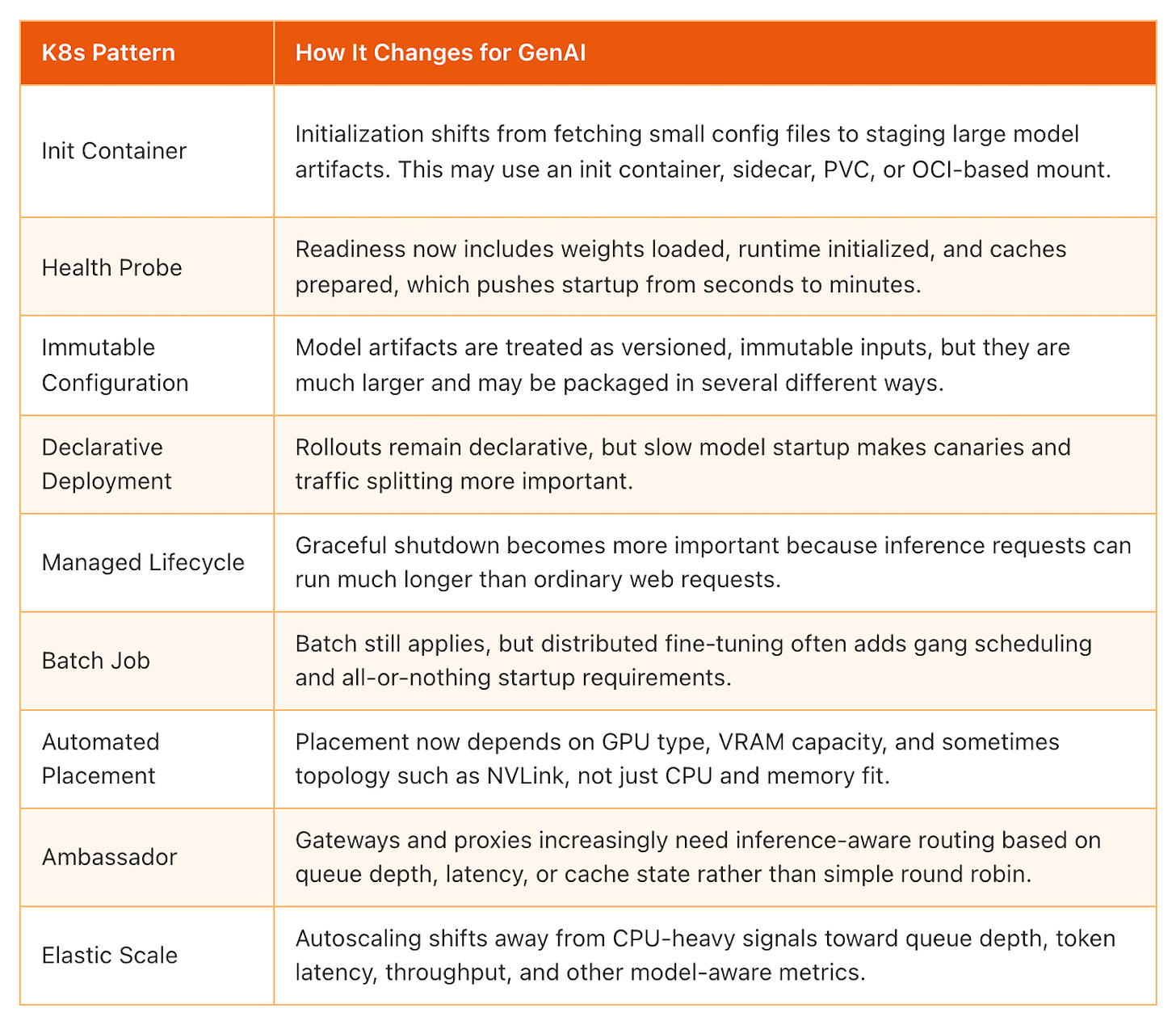
Именно здесь LLM-нагрузки начинают растягивать привычные паттерны Kubernetes. Абстракция ещё держится, но операционная реальность меняется. Секунды становятся минутами. Мегабайты становятся гигабайтами. CPU-центричные допущения перестают работать.
Новые паттерны для AI-нагрузок
Некоторые паттерны не имеют явных предшественников в каталоге Kubernetes Patterns. Они возникают из специфики LLM-нагрузок.
Model Data Staging решает задачу доставки сотен гигабайт весов модели в поды без превращения каждого масштабирования в многоминутный простой.
Token-Aware Routing заменяет round-robin на маршрутизацию, основанную на метриках: глубине очереди и состоянии KV-кэша конкретного эндпоинта. Этот подход реализуется через Gateway API Inference Extension и проекты вроде llm-d.
RAG Composition связывает воедино четыре разных типа нагрузки в одно связное приложение: оркестратор, LLM, векторная база данных и конвейер индексации. Каждый компонент естественно отображается на свой примитив Kubernetes.
Disaggregated Serving разделяет вычислительно-интенсивную фазу prefill и память-интенсивную фазу decode, запускает их на разном железе и позволяет масштабировать независимо. Этот подход реализуют такие проекты, как llm-d.
Agentic Workflows вводят LLM-агентов, которые планируют, используют инструменты и работают итеративно. Они также стимулируют появление новых протоколов: MCP (Model Context Protocol) для интеграции агентов с инструментами и A2A (Agent-to-Agent Protocol) для коммуникации между агентами.
Все эти паттерны подробно разобраны в книге Роланда и Даниэле Generative AI on Kubernetes. На KubeCon Amsterdam мы с Роландом разберём три из них: Model Data Staging, Token-Aware Routing и RAG Composition.
