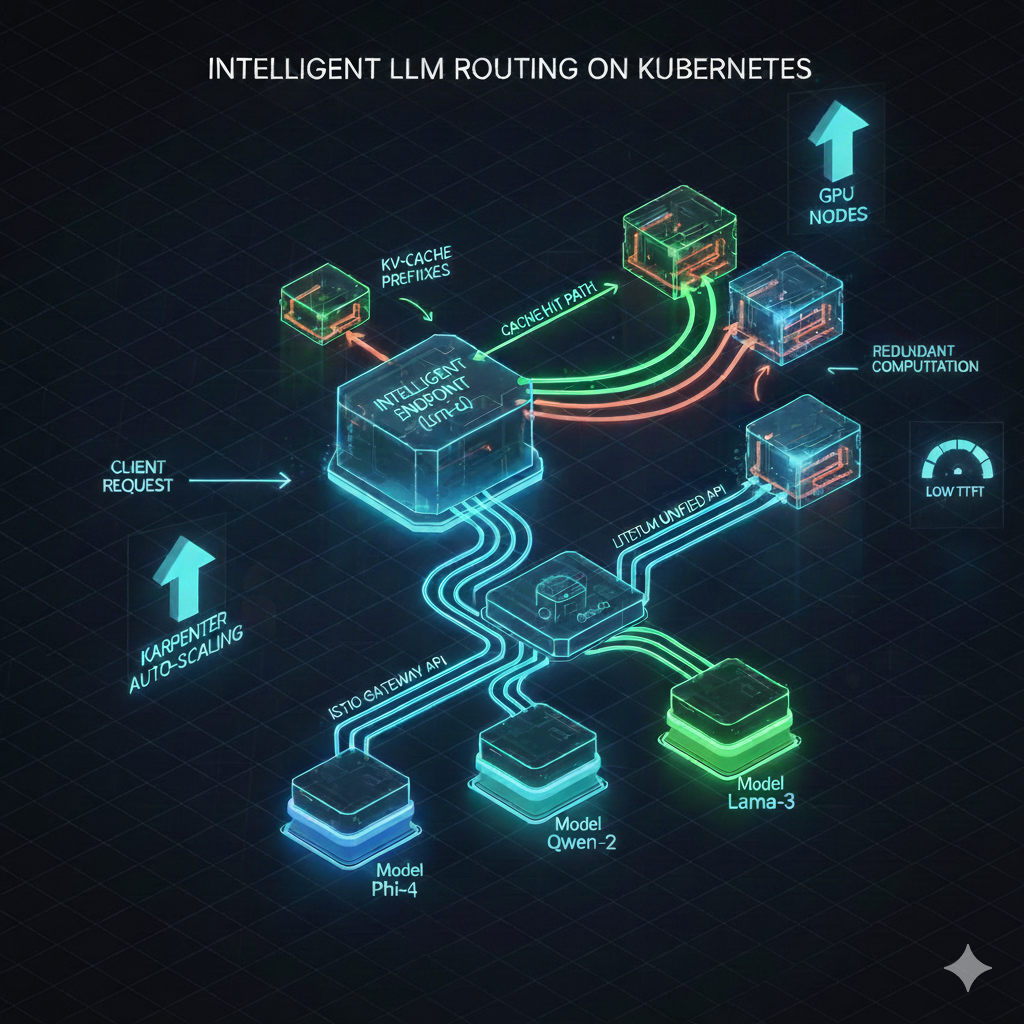
Постановка задачи
Допустим, у вас есть несколько больших и малых языковых моделей (LLM/SLM), которые нужно обслуживать на Kubernetes. Вам требуется:
-
Единый API, чтобы клиенты не знали, где именно работает та или иная модель
-
Интеллектуальная маршрутизация с учётом локальности KV-кеша для ускорения инференса
-
Изоляция каждой модели с независимым масштабированием
-
Внешний доступ по сети, чтобы другие сервисы могли обращаться к моделям
-
Оптимизация затрат на GPU — масштабирование до нуля в простое и обратно по требованию
Большинство команд решают эту задачу, развернув vLLM за LoadBalancer, и на том останавливаются. Для одной модели это работает, но схема рассыпается, как только появляется потребность в маршрутизации между моделями, планировании с учётом prefix-кеша и экономичном управлении GPU.
В этой статье рассмотрено production-развёртывание, которое закрывает все перечисленные задачи: llm-d берёт на себя интеллектуальное планирование инференса, Istio выступает провайдером Gateway API с поддержкой Inference Extension, а LiteLLM служит единым API-шлюзом.
Обзор архитектуры

Почему именно этот стек?
llm-d — это open-source Kubernetes-нативная платформа для инференса, которая добавляет интеллектуальное планирование поверх vLLM. Вместо случайной балансировки или round-robin она направляет запросы к тому поду vLLM, в GPU-памяти которого уже закешированы наиболее релевантные KV-префиксы. Результат: прирост пропускной способности на 38,9% и сокращение времени до первого токена (TTFT, Time to First Token) на 97% по сравнению с обычными сервисами Kubernetes.
Istio версии 1.28 и выше поддерживает Gateway API вместе с Inference Extension: трафик проходит через ext-proc-фильтр к Endpoint Picker (EPP) llm-d прежде, чем попасть к подам vLLM. Именно этот механизм и обеспечивает интеллектуальную маршрутизацию.
LiteLLM стоит перед всем стеком как единый OpenAI-совместимый API-шлюз, управляя API-ключами, ограничениями запросов, логированием и маршрутизацией по моделям. Клиент указывает имя модели, и LiteLLM перенаправляет запрос на нужный хост.
Ключевая идея: зачем два уровня маршрутизации?
В архитектуре два разных уровня маршрутизации, и понимание их роли принципиально важно.
Уровень 1 — LiteLLM + ALB (выбор модели): клиент говорит «хочу обратиться к Phi-4-mini», LiteLLM перенаправляет запрос на phi4.example.com. ALB сопоставляет имя хоста и передаёт трафик нужному Istio-шлюзу. Это маршрутизация на уровне модели.
Уровень 2 — Istio + EPP (выбор пода): внутри пайплайна конкретной модели EPP выбирает, какому именно поду vLLM обработать запрос, ориентируясь на попадания в prefix-кеш и текущую нагрузку. Это маршрутизация на уровне пода — то самое интеллектуальное планирование, которое предоставляет llm-d.
Объединить эти уровни в один невозможно. ALB/Ingress нужен, потому что AWS Load Balancer Controller не поддерживает ресурсы Gateway API. Gateway API с Inference Extension нужен, потому что ALB не умеет выбирать поды с учётом prefix-кеша. Оба уровня дополняют друг друга.
Реализация
Обёрточный Helm-чарт
Вместо того чтобы применять «сырые» манифесты, всё упакованово в обёрточный Helm-чарт, включающий upstream-чарт llm-d в качестве сабчарта:
llm-d-stack/
Chart.yaml # Обёрточный чарт, зависит от сабчарта llm-d
values.yaml # Базовые значения по умолчанию
cluster-values.yaml # Переопределения для конкретного кластера (конфигурация ALB, список моделей)
templates/
modelservice.yaml # CR ModelService для каждой модели
gateway.yaml # CR Istio Gateway для каждой модели
ga-inferencepool.yaml # CR InferencePool для каждой модели
ga-httproute.yaml # CR HTTPRoute для каждой модели
alb-ingress.yaml # Ресурсы ALB Ingress для каждой модели
...Массив models в values управляет всем. Достаточно добавить модель — и шаблоны сгенерируют все необходимые Kubernetes-ресурсы:
models:
- name: "Qwen/Qwen2.5-0.5B-Instruct"
resourceName: "qwen-qwen2-5-0-5b-instruct"
hostname: "qwen.example.com"
enabled: true
replicas: 1
gpu: 1
maxModelLen: 8192
gpuMemoryUtilization: "0.5"
- name: "microsoft/Phi-4-mini-instruct"
resourceName: "phi-4-mini-instruct"
hostname: "phi4.example.com"
enabled: true
replicas: 1
gpu: 1
maxModelLen: 4096
gpuMemoryUtilization: "0.5"Цепочка ресурсов для каждой модели
Для каждой модели чарт создаёт следующую цепочку:
ModelService CR (объявляет модель)
|-- Контроллер создаёт: Deployment vLLM, Deployment EPP, CR InferenceModel
Gateway CR (gatewayClassName: istio)
|-- Istio создаёт: под Gateway (прокси Envoy)
HTTPRoute (parentRef: Gateway, backendRef: InferencePool)
|-- Говорит Envoy: маршрутизировать путь "/" в InferencePool
InferencePool (endpointPickerRef: EPP, selector: decode-поды)
|-- Говорит Istio: использовать EPP как ext-proc-фильтр
Ingress (ALB, правило по имени хоста)
|-- Говорит ALB: маршрутизировать имя хоста к сервису GatewayШаблон ALB Ingress
Именно этот ресурс обеспечивает внешнюю доступность моделей. Каждая модель получает собственный ресурс Ingress, который объединяется с общим ALB через аннотацию group.name:
{{- if .Values.ingress.enabled }}
{{- range .Values.models }}
{{- if and .enabled .hostname }}
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: {{ .resourceName }}-ingress
annotations:
alb.ingress.kubernetes.io/group.name: {{ $.Values.ingress.groupName }}
alb.ingress.kubernetes.io/scheme: internal
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/certificate-arn: {{ $.Values.ingress.certificateArn }}
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}]'
alb.ingress.kubernetes.io/healthcheck-port: "15021"
alb.ingress.kubernetes.io/healthcheck-path: /healthz/ready
spec:
ingressClassName: alb
rules:
- host: {{ .hostname }}
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: {{ .resourceName }}-gateway-istio
port:
number: 80
{{- end }}
{{- end }}
{{- end }}Ключевые архитектурные решения:
-
Аннотация
group.name— несколько ресурсов Ingress с одинаковым именем группы объединяются в единый ALB. Не нужно создавать отдельный балансировщик под каждую модель. -
target-type: ip— трафик идёт напрямую к IP-адресам подов в обход NodePort. Это эффективнее и совместимо с подами Istio-шлюза. -
Health check на порт 15021 — это эндпоинт здоровья sidecar Istio (
/healthz/ready), который возвращает 200, когда под шлюза готов к работе. Поскольку целевым объектом является под Istio-шлюза, а не под vLLM, это корректно отражает готовность шлюза. -
Терминация TLS на ALB — трафик от ALB до Istio-шлюза идёт по чистому HTTP внутри VPC. Стандартная схема для внутренних сервисов.
Gateway API и Inference Extension
Ресурсы Gateway API указывают Istio, как маршрутизировать трафик внутри пайплайна каждой модели:
# Gateway — создаёт под Istio Envoy-прокси
apiVersion: gateway.networking.k8s.io/v1
kind: Gateway
metadata:
name: {{ .resourceName }}-gateway
annotations:
networking.istio.io/service-type: ClusterIP
spec:
gatewayClassName: istio
listeners:
- name: http
port: 80
protocol: HTTP
# HTTPRoute — направляет весь трафик в InferencePool
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: {{ .resourceName }}-route
spec:
parentRefs:
- name: {{ .resourceName }}-gateway
rules:
- backendRefs:
- group: inference.networking.k8s.io
kind: InferencePool
name: {{ .resourceName }}-pool
# InferencePool — связывает EPP и decode-поды
apiVersion: inference.networking.k8s.io/v1alpha2
kind: InferencePool
metadata:
name: {{ .resourceName }}-pool
spec:
targetPortNumber: 8000
selector:
matchLabels:
llm-d.ai/model: {{ modelLabel }}
endpointPickerConfig:
extensionRef:
name: {{ .resourceName }}-eppКогда запрос поступает на под Gateway, Envoy видит HTTPRoute, указывающий на InferencePool. У InferencePool есть endpointPickerConfig, ссылающийся на сервис EPP. Envoy вызывает EPP через ext-proc (фильтр внешней обработки), EPP запрашивает Redis о состоянии prefix-кеша, оценивает доступные поды vLLM и сообщает Envoy, к какому конкретному поду направить запрос.
Конфигурация LiteLLM
На стороне LiteLLM каждая модель описывается простой записью:
- model_name: qwen-0.5b
litellm_params:
model: openai/Qwen/Qwen2.5-0.5B-Instruct
api_base: https://qwen.example.com/v1
api_key: "not-needed"
- model_name: phi-4-mini
litellm_params:
model: openai/microsoft/Phi-4-mini-instruct
api_base: https://phi4.example.com/v1
api_key: "not-needed"Префикс openai/ сообщает LiteLLM, что нужно использовать OpenAI-совместимый провайдер. Имя модели после префикса должно точно совпадать с именем модели на HuggingFace, поскольку vLLM проверяет его в теле запроса. Поле api_key обязательно для LiteLLM, но vLLM его не проверяет.
Клиенты обращаются к LiteLLM, используя удобный псевдоним:
curl https://litellm.example.com/v1/chat/completions \
-H "Authorization: Bearer $API_KEY" \
-H "Content-Type: application/json" \
-d '{"model": "phi-4-mini", "messages": [{"role": "user", "content": "Hello"}]}'LiteLLM сопоставляет phi-4-mini с phi4.example.com, ALB направляет трафик к Istio-шлюзу Phi-4, а EPP выбирает оптимальный под vLLM.
Управление затратами на GPU
GPU-инстансы дороги. С Karpenter на EKS можно масштабировать кластер до нуля в период простоя:
# Масштабирование до нуля — GPU-узлы освобождаются Karpenter примерно за 2 мин
kubectl patch modelservice qwen-0-5b -n llm-d \
--type='merge' -p='{"spec":{"decode":{"replicas":0}}}'
kubectl scale deploy -n llm-d -l llm-d.ai/role=decode --replicas=0
# Масштабирование обратно — холодный старт ~5–8 мин (подготовка узла + загрузка образа + загрузка модели)
kubectl patch modelservice qwen-0-5b -n llm-d \
--type='merge' -p='{"spec":{"decode":{"replicas":1}}}'
kubectl scale deploy -n llm-d -l llm-d.ai/role=decode --replicas=1Управляющий слой (Istio-шлюзы, EPP, Redis, контроллер ModelService) продолжает работать на дешёвых CPU-узлах. Останавливаются только GPU-узлы. При масштабировании обратно Karpenter выделяет новый GPU-узел, скачивает образ vLLM (~8 ГБ) и загружает веса модели.
Важный нюанс: необходимо масштабировать и CR ModelService, и Deployment. Контроллер ModelService не синхронизирует изменения количества реплик обратно в Deployment — это известное ограничение.
Усвоенные уроки
1. В kgateway есть баг с несколькими моделями
Изначально в качестве провайдера Gateway API использовался kgateway (Solo.io). Для одной модели он работает, однако содержит баг: на один экземпляр контроллера разрешается только один InferencePool. Вторая модель всегда получает BackendNotFound. После тщательной отладки (разные модели, разный порядок, временны́е зависимости) удалось подтвердить, что баг воспроизводится в 100% случаев и не зависит от конкретной модели.
Istio 1.28 и выше с параметром ENABLE_GATEWAY_API_INFERENCE_EXTENSION=true на istiod решает эту проблему корректно — обе модели работают одновременно.
2. CRD Inference Extension для Gateway API имеют значение
Необходимы CRD Gateway API версии v1.4.0 и CRD Inference Extension версии v1.3.0. CRD Inference Extension определяют ресурсы InferencePool и InferenceModel. Без них ресурсы Gateway API молча ничего не делают.
kubectl apply -k "github.com/kubernetes-sigs/gateway-api/config/crd/?ref=v1.4.0" \
--server-side --force-conflicts
kubectl apply -k "github.com/kubernetes-sigs/gateway-api-inference-extension/config/crd/?ref=v1.3.0" \
--server-side --force-conflicts3. Маршрутизация между моделями требует внешнего роутера
llm-d — не мультимодельный роутер. Каждая модель получает собственный пайплайн: Gateway + HTTPRoute + InferencePool + EPP. EPP знает только об InferenceModel в своём пуле. Если отправить запрос для модели B на шлюз модели A, он завершится ошибкой «model not found».
Для направления запросов к шлюзу нужной модели необходимо что-то внешнее: LiteLLM, обратный прокси или DNS-маршрутизация. Это сделано намеренно — llm-d добавляет ценность внутри пайплайна одной модели (KV-кеш-маршрутизация, нагрузко-осведомлённое планирование), но не между моделями.
4. Инъекция sidecar Istio должна быть отключена
Если в кластере работает Istio с автоматической инъекцией sidecar, отключите её для пространства имён llm-d:
apiVersion: v1
kind: Namespace
metadata:
name: llm-d
labels:
istio-injection: disabledSidecar Istio мешает ext-proc-взаимодействию между подом Gateway и EPP. Сам под Gateway является прокси Envoy под управлением Istio — добавление ещё одного sidecar-прокси перед ним создаёт проблему двойного проксирования.
5. Образ vLLM по умолчанию является приватным
Образ vLLM по умолчанию в чарте llm-d (ghcr.io/llm-d/llm-d) находится в приватном реестре. Используйте вместо него публичный CUDA-вариант:
vllm:
image:
registry: ghcr.io
repository: llm-d/llm-d-cuda
tag: "v0.5.0"6. Холодный старт — это реальность
При масштабировании с нуля рассчитывайте на 5–8 минут:
-
~2 мин: Karpenter выделяет новый GPU-узел
-
~2 мин: загрузка образа vLLM (~8 ГБ)
-
~2 мин: скачивание и загрузка весов модели с HuggingFace
В production-среде рассмотрите предварительную загрузку образов (через DaemonSet), кеши pull-through в ECR или поддержание одного «тёплого» резервного узла.
Детальный разбор пути запроса
Вот что происходит, когда поступает запрос:
1. Клиент отправляет: POST https://phi4.example.com/v1/chat/completions
{"model": "microsoft/Phi-4-mini-instruct", "messages": [...]}
2. DNS разрешает phi4.example.com во внутренний ALB
3. ALB сопоставляет правило хоста "phi4.example.com"
-> пересылает на phi-4-mini-instruct-gateway-istio:80 (target-type: ip)
-> TLS терминируется на ALB, к поду идёт HTTP-трафик в открытом виде
4. Под Istio Gateway (Envoy) получает запрос
-> HTTPRoute сопоставляет путь "/"
-> backendRef указывает на InferencePool "phi-4-mini-pool"
-> InferencePool содержит endpointPickerConfig -> сервис EPP
5. Envoy вызывает EPP через ext-proc gRPC
-> EPP ищет CR InferenceModel для "microsoft/Phi-4-mini-instruct"
-> EPP запрашивает Redis: "какие поды имеют закешированный релевантный префикс?"
-> Redis возвращает: {pod-A: попадание 85%, pod-B: попадание 20%}
-> EPP оценивает: побеждает pod-A (высокое попадание в кеш + приемлемая нагрузка)
-> EPP сообщает Envoy: направить запрос на pod-A по адресу 10.x.x.x:8000
6. Envoy пересылает запрос на pod-A (vLLM)
-> vLLM обнаруживает частичное попадание в KV-кеш
-> Вычисляет только оставшиеся токены (не весь промпт)
-> Генерирует токены ответа
-> Обновляет в Redis индекс закешированных префиксов
7. Ответ возвращается обратно: vLLM -> Envoy -> ALB -> КлиентКлючевой выигрыш в эффективности — шаги 5–6: вместо случайного выбора пода EPP направляет запрос к поду с наилучшим попаданием в prefix-кеш, устраняя избыточные вычисления.
Развёртывание
# 1. Установить CRD
kubectl apply -k "github.com/kubernetes-sigs/gateway-api/config/crd/?ref=v1.4.0" \
--server-side --force-conflicts
kubectl apply -k "github.com/kubernetes-sigs/gateway-api-inference-extension/config/crd/?ref=v1.3.0" \
--server-side --force-conflicts
# 2. Убедиться, что установлен Istio 1.28+ с включённым inference extension
# 3. Создать секрет с токеном HuggingFace
kubectl create secret generic llm-d-hf-token \
--from-literal=HF_TOKEN=<your-token> -n llm-d
# 4. Развернуть
helm upgrade --install llm-d-stack ./helm/charts/llm-d-stack \
-n llm-d -f ./helm/charts/llm-d-stack/cluster-values.yaml
# 5. Проверить
kubectl get ingress -n llm-d
kubectl get pods -n llm-d
# 6. Протестировать (после настройки DNS)
curl -s https://qwen.example.com/v1/models
curl -s https://phi4.example.com/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{"model":"microsoft/Phi-4-mini-instruct","messages":[{"role":"user","content":"Hello"}],"max_tokens":10}'Что дальше
Описанная конфигурация даёт надёжную мультимодельную платформу инференса с интеллектуальной маршрутизацией. В качестве следующих шагов можно рассмотреть:
-
Разделение Prefill и Decode — вынести обработку промпта и генерацию токенов в отдельные пулы подов для снижения TTFT на длинных промптах
-
Автомасштабирование — KEDA или встроенный автоскейлер llm-d для масштабирования decode-реплик на основе глубины очереди
-
Маршрутизация LoRA-адаптеров — обслуживание дообученных вариантов моделей рядом с базовыми с поддержкой кеш-осведомлённой маршрутизации LoRA
-
Мониторинг — vLLM и llm-d экспортируют метрики Prometheus для задержки инференса, пропускной способности, утилизации GPU и глубины очереди
-
GitOps — приложения ArgoCD для обнаружения дрейфа конфигурации и самовосстановления деплоев