На протяжении многих лет развёртывание высокодоступного (HA, High Availability) кластера PostgreSQL считалось одним из «финальных боссов» администрирования баз данных. Если вы хотели получить конфигурацию, способную пережить отказ узла без ручного вмешательства, приходилось собирать сложный пазл из множества инструментов.
Я долгое время управлял этим «ручным способом», борясь с конфигурациями и следя за тем, чтобы все движущиеся части оставались синхронизированными. Но недавно я наконец решился и мигрировал на CloudNativePG, и разница оказалась огромной.
Мир изменился. С распространением Kubernetes и появлением CloudNativePG «современный способ» запуска Postgres наконец стал реальностью.
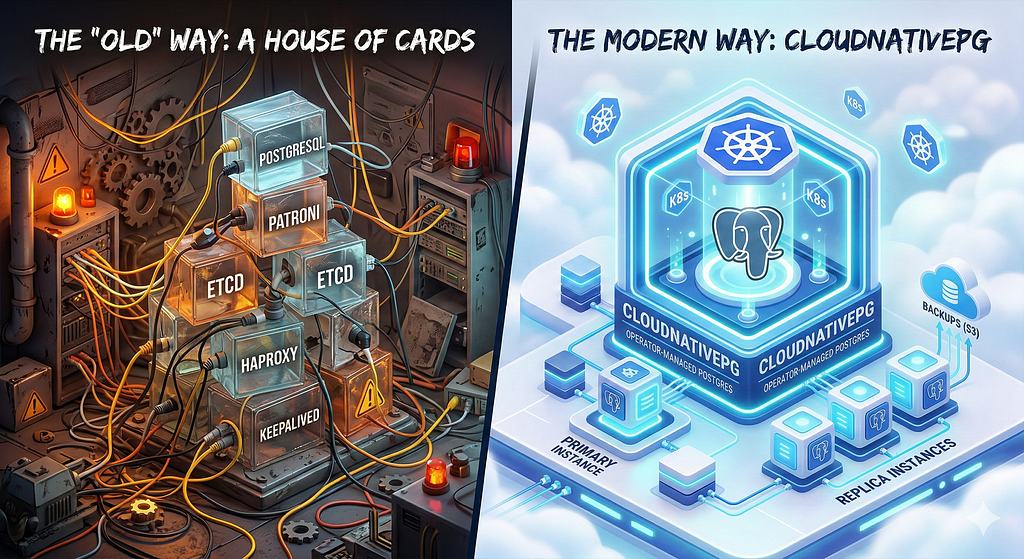
«Старый» способ: карточный домик?
До появления Kubernetes-операторов (operators) вроде CloudNativePG золотым стандартом HA для Postgres был стек, выглядевший примерно следующим образом:
-
PostgreSQL: непосредственно сама база данных.
-
Patroni: шаблон на Python для управления жизненным циклом Postgres и репликацией.
-
etcd (или Consul/Zookeeper): распределённое хранилище консенсуса, используемое Patroni для отслеживания того, кто является лидером.
-
HAProxy: обеспечивает единую точку входа для приложений, маршрутизируя трафик к текущей первичной ноде.
-
Keepalived: часто требовался для предоставления виртуального IP-адреса (VIP) для самого HAProxy.
Болевые точки
Несмотря на то что этот стек надёжен и проверен, он влечёт за собой значительные накладные расходы:
-
Сложность: вы управляете не только базой данных, но и распределённой системой (etcd), и балансировщиком нагрузки (HAProxy) поверх неё.
-
Ад конфигурации: каждый компонент имеет собственный конфигурационный файл, собственные сценарии отказов и собственные требования к масштабированию.
-
Бремя обслуживания: обновление Postgres зачастую требовало тщательной оркестрации апдейтов в Patroni при условии, что etcd оставался работоспособным на протяжении всего процесса.
-
Мониторинг: для того чтобы убедиться, что база данных «в строю», необходимо мониторить четыре или пять различных сервисов.
Современный способ: CloudNativePG
CloudNativePG (CNPG) — это оператор с открытым исходным кодом, разработанный специально для Kubernetes. Он не просто «оборачивает» Postgres — он рассматривает базу данных как нативную часть экосистемы Kubernetes.
Почему это принципиально иной подход
Самое радикальное в CNPG — это то, чего в нём нет. Он полностью устраняет необходимость в Patroni, etcd и HAProxy.
Как? За счёт того, что уже предоставляет Kubernetes.
-
etcd не нужен: CNPG использует сервер API Kubernetes в качестве источника истины для выбора лидера и состояния кластера. Если у вас есть работающий кластер K8s, у вас уже есть необходимый уровень консенсуса.
-
Patroni не нужен: сам оператор управляет жизненным циклом инстансов, репликацией и логикой отказоустойчивости нативно.
-
HAProxy не нужен: CNPG создаёт нативные Kubernetes Services, которые автоматически маршрутизируют трафик к первичной ноде или репликам.
Ключевые преимущества CloudNativePG
Декларативное управление
Всё является пользовательским ресурсом (Custom Resource, CR). Вы описываете кластер в YAML-файле:
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: my-database
spec:
instances: 3
storage:
size: 1GiПримените этот файл — и у вас готов HA-кластер из 3 узлов. Нужно больше реплик? Просто измените instances: 3 на instances: 5.
Самовосстановление
Если узел выходит из строя, оператор CNPG немедленно это замечает. Он повышает реплику до первичной, обновляет Kubernetes Services и запускает новый инстанс для поддержания желаемого количества. Всё автоматически, без ручного вмешательства.
Встроенные резервные копии
CNPG имеет нативную поддержку barman-cloud-wal-archive и barman-cloud-backup, поэтому вы можете передавать WAL-логи и резервные копии напрямую в S3, GCS или Azure Blob Storage с помощью всего нескольких строк конфигурации.
Обновления без простоя
Оператор может выполнять скользящие обновления (rolling updates) инстансов Postgres, так что ваше приложение остаётся онлайн даже во время патчинга движка базы данных.
Сравнение на первый взгляд

Практикум: развёртывание CloudNativePG с помощью Terraform
Хватит теории — давайте засучим рукава. В этом разделе я проведу вас через развёртывание готового к продакшену кластера CNPG с использованием Terraform. Если вы предпочитаете чистый kubectl и YAML, те же концепции применимы и там. Terraform просто добавляет воспроизводимость и управление состоянием.
Шаг 1: Установка оператора CNPG
Прежде всего нам нужен сам оператор. Helm-чарт создаст для нас пространство имён:
# Deploy CloudNative-PG Operator
resource "helm_release" "cloudnative_pg" {
name = "cloudnative-pg"
repository = "https://cloudnative-pg.github.io/charts"
chart = "cloudnative-pg"
version = "0.27.0"
namespace = "cnpg-system"
cleanup_on_fail = true
create_namespace = true
}Это устанавливает оператор через его официальный Helm-чарт. Оператор отслеживает пользовательские ресурсы Cluster во всех пространствах имён и управляет инстансами PostgreSQL соответствующим образом.
Шаг 2: Установка плагина Barman Cloud
Помните встроенную поддержку резервного копирования, о которой я упоминал ранее? Для её использования вам понадобится плагин Barman Cloud:
# Deploy Barman Cloud Plugin for backup management
resource "helm_release" "barman_cloud" {
name = "plugin-barman-cloud"
repository = "https://cloudnative-pg.github.io/charts"
chart = "plugin-barman-cloud"
namespace = "cnpg-system"
cleanup_on_fail = true
create_namespace = false
depends_on = [
helm_release.cloudnative_pg
]
}Этот плагин включает архивирование WAL и создание базовых резервных копий в S3-совместимое хранилище, GCS или Azure Blob Storage.
Шаг 3: Развёртывание производственного кластера
Чтобы упростить развёртывание полноценного кластера CNPG, я написал Terraform-модуль, который объединяет конфигурацию кластера, создание баз данных, настройку резервного копирования и управление секретами в единый переиспользуемый модуль. Он всё ещё находится в активной разработке и пока не идеален, но уже берёт на себя основную нагрузку для большинства сценариев использования.
Вот реальный пример с постоянным хранилищем и автоматическим резервным копированием:
# Generate a secure password for the database user
resource "random_password" "my_app_user" {
length = 32
special = false
}
module "postgres_cluster" {
source = "github.com/pascalinthecloud/terraform-module-cnpg-database?ref=v0.0.6"
databases = [
{
name = "my-app-postgres"
owner = "my_app_user"
password = random_password.my_app_user.result
reclaim_policy = "Retain"
create_connection_secret = true
connection_secret_namespace = "my-app"
}
]
cluster = {
name = "postgres-cluster"
namespace = kubernetes_namespace.databases.metadata[0].name
instances = 3
storage_class = "your-storage-class" # e.g. longhorn, rook-ceph, gp3, etc.
storage_size = "20Gi"
postgresql_max_connections = "200"
}
labels = {
app = "postgres-cluster"
environment = "production"
managed-by = "terraform"
}
backup = {
enabled = true
s3_endpoint_url = "https://s3.example.com:9000"
s3_bucket_name = var.backup_bucket_name
s3_access_key_id = var.s3_access_key_id
s3_secret_access_key = var.s3_secret_access_key
retention_policy = "90d"
schedule = "0 2 * * *" # Daily at 2 AM UTC
wal_compression = "gzip"
data_compression = "gzip"
target = "prefer-standby"
create_scheduled_backup = true
}
}Что именно мы получаем?
-
HA-кластер из 3 инстансов с автоматическим переключением при отказе: один первичный узел и две реплики.
-
Выделенная база данных и пользователь с Kubernetes Secret, содержащим строку подключения, автоматически созданным в пространстве имён приложения. Приложение просто монтирует секрет — никаких жёстко заданных учётных данных.
-
Автоматическое ежедневное резервное копирование в 2:00 UTC с gzip-сжатием, передаваемое в S3-совместимое хранилище. Архивирование WAL также включено, что обеспечивает восстановление до произвольной точки во времени (point-in-time recovery).
-
90-дневный срок хранения, позволяющий восстановиться после проблем, обнаруженных спустя долгое время после их возникновения.
-
Цель
prefer-standbyозначает, что резервное копирование выполняется с реплики, так что первичный узел не испытывает дополнительной нагрузки.
Добавление дополнительных баз данных
Нужно ещё одно приложение, работающее с тем же кластером? Просто добавьте ещё одну запись в список databases:
databases = [
{
name = "my-app-postgres"
owner = "my_app_user"
password = random_password.my_app_user.result
reclaim_policy = "Retain"
create_connection_secret = true
connection_secret_namespace = "my-app"
},
{
name = "another-service-postgres"
owner = "another_service_user"
password = random_password.another_service_user.result
reclaim_policy = "Retain"
create_connection_secret = true
connection_secret_namespace = "another-service"
}
]Каждая база данных получает собственного пользователя, собственный секрет с учётными данными и собственную изоляцию по пространству имён — всё на одном и том же HA-кластере.
Мониторинг
Помните, что «старый» способ требовал мониторинга четырёх-пяти различных сервисов? С CloudNativePG мониторинг достаётся практически бесплатно. Оператор автоматически разворачивает ресурс PodMonitor, а это значит, что если в вашем кластере запущен Prometheus, он начнёт собирать метрики с ваших инстансов PostgreSQL прямо из коробки. Никакой дополнительной конфигурации не требуется.
Для визуализации этих метрик вы можете импортировать официальный дашборд CloudNativePG для Grafana. Он даёт полный обзор вашего кластера: состояние инстансов, статус репликации, количество подключений, использование процессора и памяти, интенсивность транзакций и многое другое.
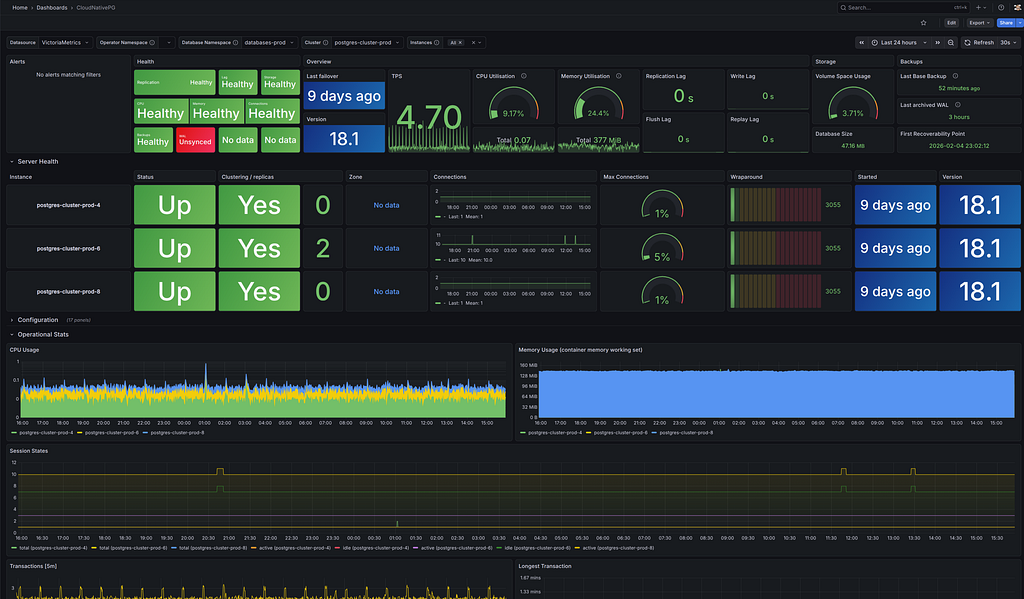
Так выглядит мой производственный кластер. Все три инстанса здоровы, репликация синхронизирована, использование ресурсов видно с первого взгляда. Сравните это со «старым» способом: проверкой логов Patroni, запросами к etcd и отдельной верификацией бэкендов HAProxy.
Заключение
Эпоха «самостоятельной сборки» HA-стека для Postgres подходит к концу для тех, кто работает на Kubernetes. CloudNativePG предлагает упрощённый, «скучный» (в хорошем смысле!) подход к управлению базами данных, позволяющий сосредоточиться на данных, а не на инфраструктуре.
Путь от нуля до готового к продакшену, защищённого резервными копиями, высокодоступного кластера PostgreSQL занимает всего несколько Terraform-ресурсов. Сравните это с ручной настройкой Patroni, etcd и HAProxy — разница колоссальная.
Если вы работаете на Kubernetes, CloudNativePG — это не просто один из вариантов, это современный стандарт.