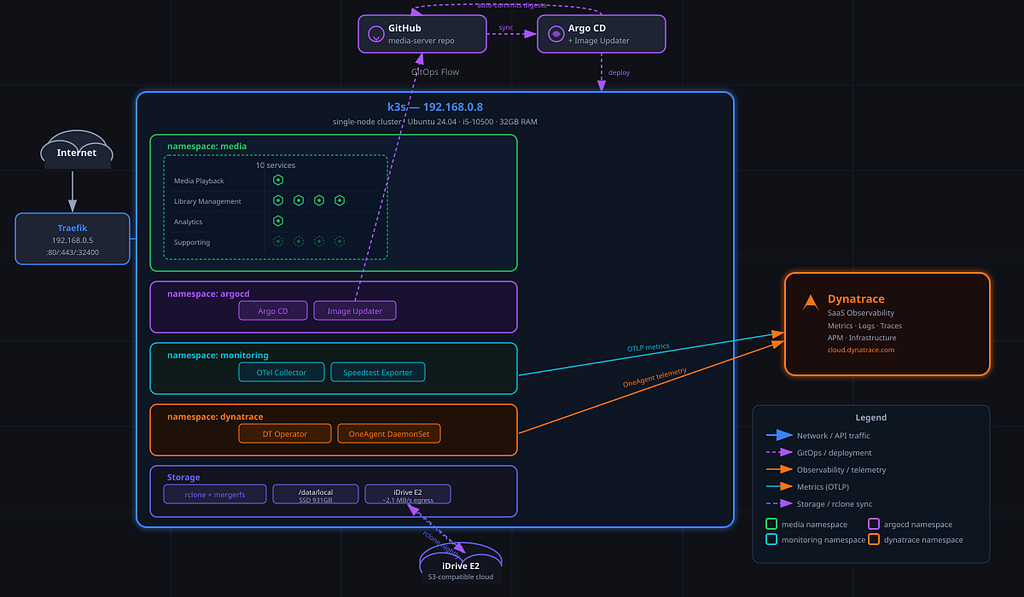
На полке в моём домашнем офисе стоит Lenovo ThinkCentre. Процессор Intel i5, 32 ГБ оперативной памяти, SSD на 1 ТБ, Intel UHD 630 для аппаратного транскодирования — ничего особенного. Но вот что одна неделя вайб-кодинга (vibe coding) с Claude Code позволила развернуть на этой машине — это уже другая история: десять контейнеризированных сервисов — Plex для воспроизведения медиа, Radarr, Sonarr и Lidarr для управления библиотекой, Tautulli для аналитики и четыре вспомогательных сервиса — развёрнутые через GitOps на k3s, автоматически обновляемые с помощью Argo CD Image Updater (каждое изменение дайджеста образа превращается в автоматический git-коммит) и полностью отслеживаемые Dynatrace с конвейером OTel, который в реальном времени собирает метрики передачи rclone и результаты speedtest.
Но вот в чём настоящая история. Я годами держал версию этого стека на bare metal. Всё работало нормально — до тех пор, пока не понадобилось новое железо. И вдруг передо мной замаячили недели работы: половина конфигурации жила у меня в голове, остальное было разбросано по заметкам и мышечной памяти. Это ловушка, которую знает каждый инженер на личных проектах. Железо ломается, ты идёшь дальше, проходит год — и та ментальная модель, что была, исчезает. Восстанавливать с нуля систему такой сложности — это не задача на выходные.
Так что приобретение нового железа стало тем самым триггером. Вместо того чтобы копировать файлы и надеяться, что ничего не сломается, я решил использовать это как возможность: изучить Claude Code и построить систему, которую можно действительно восстановить. Не просто «запустить снова», а восстановить как следует: задокументированную, автоматизированную, воспроизводимую на любом железе — из резервной копии, человеком, который забыл половину деталей. Вот та планка, к которой я стремился.
Я строил это по вечерам в течение одной недели. Мои знания Kubernetes на входе: теоретические. Я знал, что такое под (pod). Я никогда не писал манифест.
Очевидное предположение: ты позволяешь Claude Code всё построить за тебя. Этот фрейм неверен, и, думаю, стоит объяснить почему — особенно сейчас, когда компании спускают сверху директивы «AI-first», а инженеры пытаются разобраться, что это реально означает для их работы.
-
Настоящая цель была не в том, чтобы построить медиасервер, — а в том, чтобы вырваться из ловушки хрупкости: система была настолько вручную сконфигурирована, что отказ железа означал недели восстановления по памяти.
-
От нулевого опыта в Kubernetes до GitOps-стека — за одну неделю вечеров. ИИ сжал кривую обучения; каждое значимое решение принималось на основе доменных знаний.
-
ИИ сжёг целое контекстное окно, ходя по кругу над одной проблемой. Десятиминутный разговор с человеком-экспертом её решил. Умение вовремя остановиться — по-прежнему инженерный навык.
Что на самом деле означает «вайб-кодинг»
Этот термин заслужил немало закатывания глаз — в основном потому, что люди представляют себе, как кто-то набирает «сделай мне приложение» в чатбот и выкладывает всё, что вернулось. Если это ваше определение — ладно, отмахнитесь. Но не то делал я, и не это имеет в виду термин для тех, кто действительно пробовал строить что-то нетривиальное таким образом.
Небольшое замечание об инструментах: Claude Code — это не инструмент автодополнения в IDE. Это агентная (agentic) среда — у неё есть полный доступ к вашему репозиторию, она может выполнять команды в оболочке, читать и записывать файлы, и сохраняет контекст на протяжении всего проекта через интерфейс беседы. Если вы пользовались GitHub Copilot, вы знаете автодополнение, понимающее вашу кодовую базу. Claude Code — это другая категория: вы ведёте с ней архитектурный диалог, и она может действовать непосредственно в вашей кодовой базе. Потолок выше, и стоимость тоже выше — неделя интенсивных агентных сессий обходится в десятки долларов за использование API. Это стоит знать заранее.
То, что я практиковал, — итеративный, диалоговый рабочий процесс. Я определял намерение и архитектуру. Claude Code занималась деталями реализации, шаблонным кодом и когнитивной нагрузкой — держать в контексте конфигурацию десяти сервисов одновременно. Я проверял архитектурные решения и возражал, когда что-то было неправильным. Я не проверял каждую строку манифеста контроллера Sealed Secrets — для этого я доверял официальному релизу, — но каждое решение, определявшее, как система работает, было моим.
Ключевым механизмом стал файл CLAUDE.md — живой архитектурный документ, зафиксированный в репозитории, который Claude читает в начале каждой сессии. Думайте о нём как об общей памяти: документ, который ИИ читает перед каждым разговором, чтобы никогда не терять из виду то, что вы уже решили. Характеристики железа, схема хранения, топология сети и каждое проектное решение с обоснованием. Всякий раз, когда я возражал и мы приходили к лучшему варианту, этот ответ попадал в CLAUDE.md. К концу недели это было самое точное описание системы из всех существующих — лучше любой вики, потому что обновлялось в реальном времени по мере принятия решений.
Claude Code умеет моделировать сценарии отказа, рассуждать о том, что первым сломается на пустой системе, читать события подов (pod events) и диагностировать петлю перезапуска в полночь. Чего она не умеет — так это измерять ваше окружение, говорить вам, когда что-то кажется неправильным, или знать, что вам на самом деле важно. Это не живёт ни в какой модели. Это оставалось за мной.
Что реально производит неделя вайб-кодинга
Железо: Lenovo ThinkCentre, процессор Intel i5, 32 ГБ RAM, зашифрованный SSD на 1 ТБ, Intel UHD 630 для аппаратного транскодирования. Ubuntu 24.04 с полнодисковым LUKS-шифрованием и Dropbear SSH для удалённой разблокировки при загрузке.
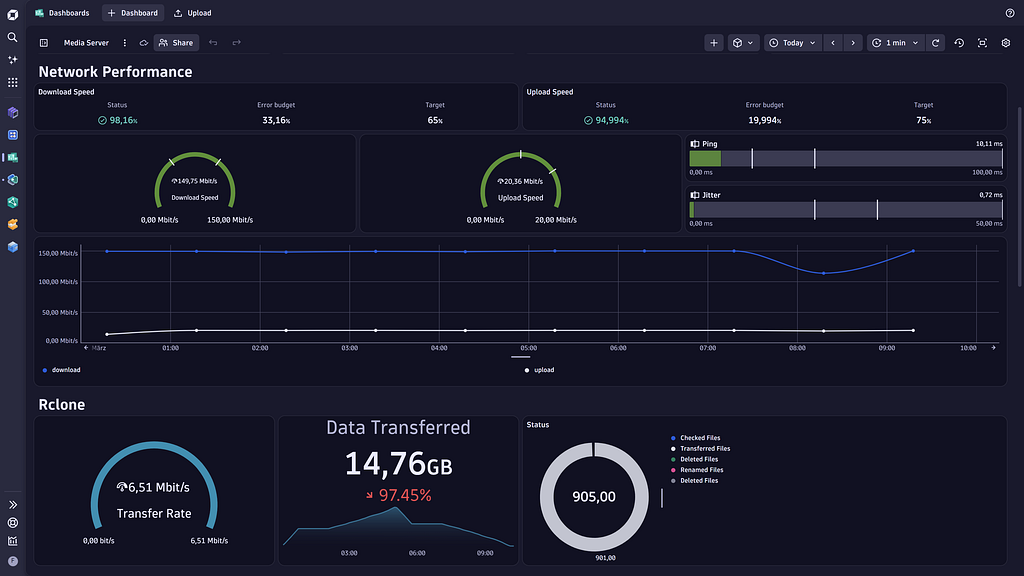
Хранилище: мне нужно было, чтобы медиафайлы на локальном SSD и в облаке выглядели как единая библиотека. rclone обеспечивает подключение к облаку (iDrive E2); mergerfs объединяет локальный SSD и облачное монтирование в единый путь /data/media, который Plex читает, не зная и не заботясь о том, где физически находятся файлы. Кэш VFS ограничен 20 ГБ на локальном SSD, чтобы «горячий» контент оставался быстрым. Измеренный исходящий трафик из iDrive E2: ~2,1 МБ/с. Это число важно — я вернусь к нему.
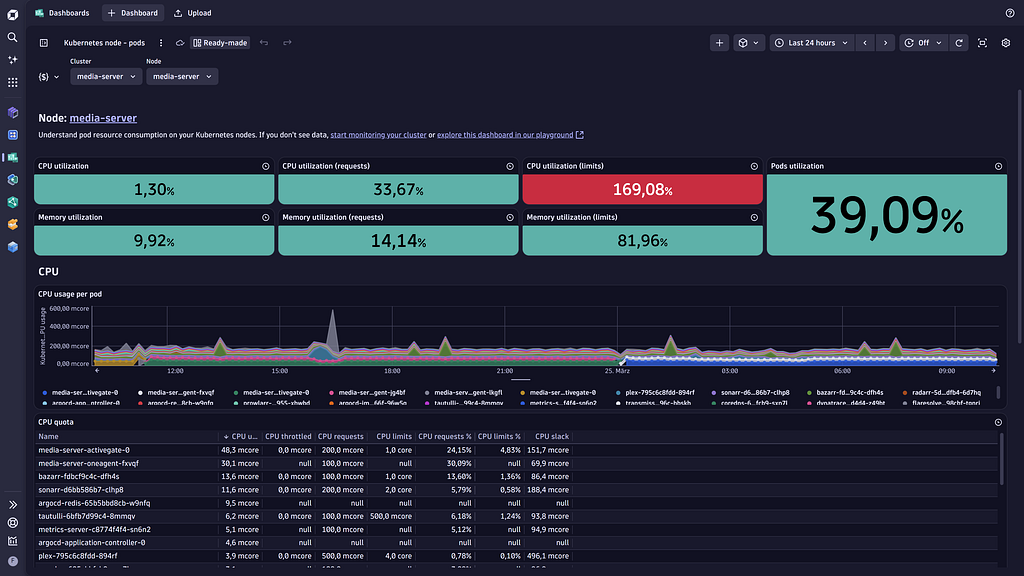
Вычисления: k3s — лёгкий дистрибутив Kubernetes, подходящий для одноузловых установок. Десять медиасервисов, каждый с ограничениями ресурсов, настроенными под железо, и все три типа проб настроены (startup, liveness, readiness). k3s намеренно не является высокодоступным (high-availability); это одна машина, одна плоскость управления (control plane). Это компромисс, который я принял в обмен на простоту — и тот, от которого конвейер резервного копирования и восстановления спроектирован быстро оправляться, когда железо в конце концов выйдет из строя. Plex получает 4 ядра CPU и 8 ГБ RAM в качестве лимита. /dev/dri/renderD128 монтируется в контейнер для аппаратного транскодирования, LIBVA_DRIVER_NAME=iHD задаётся в окружении, чтобы драйвер iHD VA-API реально подхватывался.
GitOps: Argo CD v3.3.4 и Image Updater v0.15.1. Репозиторий — единственный источник истины. Image Updater опрашивает реестры, закрепляет новые дайджесты в kustomization.yaml каждого сервиса и автоматически коммитит в main. В моём git-логе есть записи вида build: automatic update of plex — это кластер сообщает мне о том, что изменил, а не я что-то делаю вручную. Для сольного проекта прямые коммиты в main вполне подходят. В командном контексте вы бы направляли их через pull-реквесты с гейтами одобрения — механизм тот же, слой управления (governance layer) располагается поверх.
Наблюдаемость (Observability): Dynatrace Kubernetes Operator v1.8.1 в режиме cloudNativeFullStack (DaemonSet OneAgent на узле), OTel Collector, собирающий данные с Prometheus-эндпоинта /metrics rclone и экспортера speedtest, DaemonSet logMonitoring для логов подов. Ежедневные резервные копии отправляются на отдельную машину в домашней сети через rclone; скрипт резервного копирования также выполняет обнаружение дрейфа конфигурации (config drift detection) и передаёт предупреждения в Dynatrace. Тестовое восстановление (restore dry-run) автоматически запускается 1-го числа каждого месяца в 04:00.
Как это происходило на самом деле
День первый: десять сервисов, ноль предыдущих манифестов
Медиасервер заработал уже через несколько часов в первый день. Десять контейнеров, проверки работоспособности, ограничения ресурсов и аппаратное транскодирование настроены. До того вечера я никогда не писал манифест.
Скорость — самое простое, на что можно указать, но это не самое интересное. Меня удивило, насколько много я узнал в процессе. Claude не просто генерировала YAML — она объясняла каждое решение. Я спросил, почему Recreate вместо RollingUpdate для сервисов с состоянием (stateful services), и получил чёткий ответ: два экземпляра Radarr, пишущих в один каталог конфигурации одновременно, повредят базу данных. Я спросил, что делает storageClassName: "" в определении PersistentVolume, и получил объяснение того, как локальный провайзионер (local-path provisioner) k3s автоматически привязывает PVC и почему от него отказываются, чтобы управлять привязкой самостоятельно. Я не читал документацию от начала до конца. Я строил что-то реальное и задавал вопрос «почему» на каждом шаге, получая ответы, точно соответствующие тому, что именно я строил.
Первый настоящий момент отладки: под Bazarr в постоянной петле перезапуска. kubectl describe pod поначалу не давал ничего ясного. Claude прочитала манифест, прочитала события пода и нашла причину: проба liveness обращалась к /ping, но Bazarr с включённой аутентификацией возвращает там 401, которую проба интерпретирует как сбой, что вызывает перезапуск, который снова запускает пробу. По кругу. Исправление — переключиться на TCP-пробу — было делом секунд, как только причина стала ясна. Без помощи я часами рылся бы в документации Bazarr и конфигурации проб Kubernetes.
Измерение реальности: когда значение по умолчанию было в 8 раз слишком медленным
История с настройкой rclone — самый наглядный пример того, почему ИИ не может заменить инженерное суждение.
В начальной конфигурации VFS использовалось ReadAhead=128MB. Разумное значение по умолчанию — идея в том, что вы буферизуете данные впереди воспроизведения, чтобы сетевые сбои не прерывали поток. Проблема: реальный исходящий трафик iDrive E2 к моему дому составляет ~2,1 МБ/с. При такой скорости 128 МБ буферизуются за 128 ÷ 2,1 = 61 секунду до начала воспроизведения. При каждой попытке что-то посмотреть я сидел перед пустым экраном целую минуту.
Claude установила ReadAhead=128MB, потому что это правильное значение по умолчанию для быстрого соединения. У неё не было никакой возможности знать мою реальную скорость исходящего трафика — она существует только в моём окружении, и только если кто-то её измерит. Я измерил, сделал математику и снизил значение до 16 МБ. При 2,1 МБ/с 16 МБ буферизуются за 7,6 секунды. В восемь раз быстрее. Математика проста, когда есть правильный входной параметр. Правильный входной параметр потребовал человека, который мог заметить, что что-то кажется медленным, и выяснить почему.

Миграция на Argo CD: один день, одно архитектурное решение
Было несколько архитектурных моментов, где я возражал. Как структурированы логи. Где должна жить конфигурация — ConfigMap, переменная окружения или монтируемый файл. Как следует организовать манифесты перед миграцией на Argo CD. Мой подход каждый раз: «Вот альтернатива. Объясни мне компромиссы». Не «ты не прав» — просто принуждение к сравнению. Результат неизменно оказывался лучше любой из исходных позиций. Claude привносила соглашения Kubernetes и знание реализации; я привносил понимание того, как эта система будет реально эксплуатироваться. Оба аспекта имели значение.
Сама миграция на Argo CD произошла за один день, примерно в середине недели. Переход от плоских манифестов к поддиректориям для каждого сервиса — каждая со своим kustomization.yaml — выглядит как рефакторинг, но это архитектурное решение. Оно открыло возможность гранулярных Argo CD Applications (откатить один сервис, а не весь кластер), закрепление дайджестов Image Updater в рамках отдельного сервиса и git-историю, по которой можно отследить, какой коммит обновил какой образ. Claude спроектировала структуру. Я её одобрил.
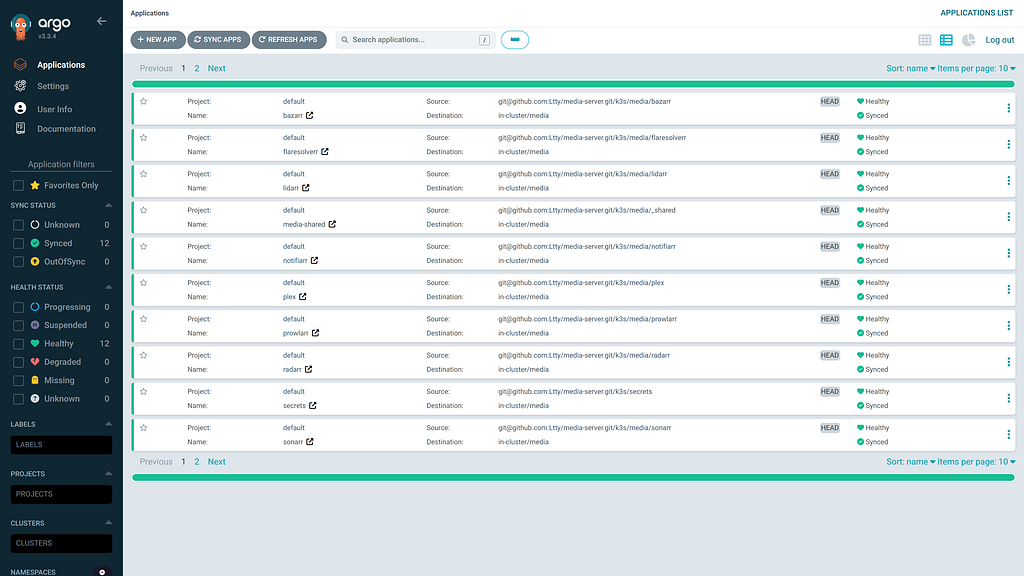
Одна вещь, которая нас подловила: удалённые URL в kustomization.yaml не работают внутри движка kustomize Argo CD. Контроллер Sealed Secrets изначально был определён как URL GitHub-релиза. Argo CD не может получать данные с внешних URL во время применения (apply time) — он ожидает, что всё находится в репозитории. Мы скачали манифест на 413 строк и зафиксировали его локально. GitOps означает, что git — источник истины. Не URL. Не «получу это во время применения». Репозиторий.
Где Claude уткнулась в тупик: проблема с Dynatrace Operator
История с наблюдаемостью — та, в которой я честен больше всего, потому что именно здесь ИИ не просто упёрся в стену — он ходил по кругу, пока не исчерпал все ресурсы.
Когда я пришёл в Dynatrace, я установил автономный OneAgent прямо на bare metal хост, чтобы разобраться в технологии. Это работало нормально: метрики хоста поступали, статистика передачи rclone приходила через OTel Collector. Чего у меня не было — нативного контекста Kubernetes: логи подов не коррелировали с кластером, в Dynatrace не было метаданных на уровне сервисов.
Разумное решение: добавить Kubernetes Operator с режимом applicationMonitoring и включить DaemonSet logMonitoring. Документация описывает это в нескольких шагах. Я следовал им. Под logMonitoring не запускался — exit 128, бинарный файл начальной загрузки не найден. Operator создавал DaemonSet, но не монтировал CSI-модуль кода в init-контейнер. Был ли это баг или ожидаемое поведение с applicationMonitoring — я не мог разобраться.
Вот тут всё стало дорогостоящим. Claude Code потратила целую сессию — всё контекстное окно, все токены — на патчинг манифестов, корректировку конфигурации DynaKube, проверку вариантов. Ничего не работало. И чем больше я наблюдал за итерациями, тем сильнее становилось моё интуитивное ощущение: это не проблема манифеста. Что-то архитектурно неправильно, и мы исправляем не то.
Я прервал сессию и написал напрямую разработчику Dynatrace Operator. Ответ был полезным: комбинация, которую я запускал, — bare metal OneAgent, Operator с applicationMonitoring, DaemonSet logMonitoring — никогда не была предназначена или протестирована совместно. Это не задокументированный режим сбоя; это просто непроверенный путь, о котором никто не думал. Рекомендация: перейти на cloudNativeFullStack, убрать агент bare metal, получить всё от единой управляемой установки.
Я попробовал установить CNFS. Получил явную ошибку конфликта — нельзя запустить DaemonSet cloudNativeFullStack и bare metal OneAgent на одном узле, установка отказывает. Удалил bare metal агент. Применил манифест DynaKube с CNFS. Всё поднялось. Логи подов скоррелировались. Полные метаданные Kubernetes в Dynatrace. Целый день того, как Claude сжигала токены на неправильную проблему, — решён за один разговор с нужным человеком.
То, что Claude не могла мне сказать, не было ни в какой публичной документации. Архитектурная комбинация была непроверенной. Никакое количество итераций с манифестами не могло это исправить. Только человек, знающий внутренности системы, мог это выявить.
Конечное состояние: DaemonSet OneAgent на узле, метрики подов и хоста в Dynatrace, статистика передачи rclone и результаты speedtest поступают через OTel, логи подов собираются, дрейф конфигурации обнаруживается ежедневно.
Где ИИ на самом деле даёт сбои
Хочу быть прямолинейным в этом вопросе, потому что большинство рассуждений в духе «ИИ не заменит инженеров» — либо расплывчатое успокоение, либо защитный перебор. Вот что я реально встретил.
ИИ не может измерить ваше окружение. Он не знает, что ваш облачный провайдер выдаёт исходящий трафик 2,1 МБ/с вместо 150 Мбит/с. Он не знает задержку вашего диска или топологию вашей сети. Конфигурация, которую он генерирует, структурно корректна — калибровать её к вашей реальности — ваша задача.
ИИ не знает, когда что-то кажется неправильным. 61 секунда — это число. «Это неприемлемо» — это суждение. Этот разрыв — инженерный опыт, и никакая модель его не заполняет.
ИИ не может отлаживать то, что не задокументировано — и не всегда говорит вам, когда застрял. Claude сожгла целое контекстное окно на проблеме logMonitoring, итерируя по манифестам для архитектурной комбинации, которая никогда не тестировалась. Она продолжала пробовать, потому что именно это она и делает. У неё не было способа узнать, что проблема не в манифестах. Именно я должен был заметить, что мы ходим по кругу, и остановиться. Умение распознать, когда нужно остановиться и эскалировать — по-прежнему человеческое суждение.
У ИИ нет архитектурного вкуса. ConfigMap против Secret против переменной окружения. Где живёт конфигурация. Как называются вещи. Эти решения кажутся мелкими и плохо накапливаются. Принять их правильно требует суждения, которое формируется за годы обслуживания систем, а не из чтения спецификаций.
ИИ не может знать, чего вы на самом деле хотите. «Настрой наблюдаемость» охватывает очень много. То, что Dynatrace-native был правильным ответом в моём случае — потому что я там работаю и знаю архитектуру — было информацией, которой только я располагал. ИИ выполнял намерение, которое я ему дал. Намерение было моим.
Для чего ИИ реально хорош
Вот что меня реально впечатлило после недели использования его для настоящей инфраструктурной работы.
Он сжимает кривые обучения так, как не делает ничто другое. От нулевого практического опыта в Kubernetes до понимания наложений (overlays) kustomize, Sealed Secrets, git write-back Image Updater, сетевых служб k3s и привязки PersistentVolume — за одну неделю. Не через чтение документации, а через построение чего-то реального и вопрос «почему» на каждом шаге с немедленными ответами, точно соответствующими тому, что именно вы строите. Петля обратной связи тесная, потому что контекст специфичен для вашего проекта.
Он рассуждает о режимах отказа, для тестирования которых у вас нет живого окружения. Ежемесячный тестовый прогон восстановления — restore.sh --dry-run, 1-е число каждого месяца в 04:00 — был спроектирован целиком через рассуждение о том, что первым сломается на пустой системе. Никакой пустой системы не потребовалось. Claude проработала порядок зависимостей, сценарии частичного восстановления, как выглядит сломанная резервная копия. Дизайн появился из разговора. Этот тестовый прогон уже поймал сломанный путь резервной копии Bazarr, который я изменил, не обновив скрипт, — тихо, в 4 утра, зафиксировав в Dynatrace ещё до того, как я выпил свой утренний кофе. В этом суть построения надёжности с ИИ: вы не просто устраняете сегодняшние проблемы — вы рассуждаете о тех, на которые ещё не наткнулись.
Он удерживает контекст, который перегрузил бы одну рабочую сессию. CLAUDE.md становится памятью проекта. Каждое решение задокументировано, каждый компромисс записан. После дня отсутствия мне не нужно было восстанавливать состояние — всё было там. Проект длиной в неделю, который обычно живёт в голове одного человека, получил письменную запись каждого значимого выбора.
И да — отладчик в полночь. Поды перезапускаются в петле в 23:00, инструмент умеет читать манифест, читать события пода, точно объяснить, почему /ping возвращает 401 с включённой аутентификацией, и передать вам исправление. Альтернатива — вы, Stack Overflow и постепенно нарастающее осознание того, что придётся не спать ещё долго.
AI-first не означает AI-only
Если вы инженер в компании, которая спустила сверху директиву «AI-first», вы наверняка заметили, что директива не поставляется с определением. И негласный подтекст — иногда высказываемый прямо — в том, что человеческое суждение является узким местом, которое нужно устранить.
Это в корне неверно.
Правильный фрейм проще: ИИ убирает трение между тем, что вы понимаете, и тем, что вы можете построить.
Я понимал Kubernetes концептуально. Я понимал свои ограничения по хранилищу. Я знал, каково это — 61 секунда. Я знал архитектуру Dynatrace, потому что там работаю, и именно это знание в конечном счёте разблокировало конфликт с Operator. Чего у меня не было — синтаксис, шаблонный код, мышечная память с kubectl, способность держать десять сервисов в рабочей памяти при конфигурировании следующего.
ИИ дал мне всё это. Моё суждение дало ему направление.
Инженеры, которые извлекут из этих инструментов максимум, — не те, кто всё передаёт и принимает то, что возвращается. Это те, кто вовлекается критически, привносит то, что знает, в разговор, ставит под сомнение инструмент, когда что-то не сходится, и знает, когда проблема требует человека-эксперта. История с Dynatrace Operator тому доказательство: ИИ был полезен почти для всего в этом проекте, и была ровно одна проблема, которую он не мог решить. Умение видеть это различие — и взять трубку — по-прежнему инженерный навык.
Медиасервер работает. Каждое обновление образа — это git-коммит. Каждая резервная копия ежемесячно проверяется тестовым прогоном, который выполняется без моего участия. Dynatrace видит полную картину. Неделя вечеров, один потребительский ПК, человек, который никогда не писал манифест Kubernetes.
А ловушка хрупкости? Исчезла. Система больше не держится на памяти и мышечной памяти. Она задокументирована, автоматизирована и воспроизводима — файл CLAUDE.md точнее любого runbook, который я когда-либо писал, потому что обновлялся в реальном времени по мере принятия каждого решения. Отказ железа теперь — упражнение по восстановлению, а не перестройка с нуля.
Тот же принцип применим независимо от того, работаете ли вы над домашним проектом или выкатываете фичу в кодовой базе с десятилетней историей и командой из пятнадцати инженеров. Инструменты и масштаб различаются. Динамика — нет: ИИ убирает трение; ваше суждение определяет, стоит ли им пользоваться.
Это не ИИ, заменяющий инжиниринг. Это то, что происходит, когда трение исчезает.
FAQ
Что такое вайб-кодинг?
Вайб-кодинг (vibe coding) — итеративный, диалоговый рабочий процесс, при котором инженер определяет намерение и архитектуру, а ИИ занимается деталями реализации и шаблонным кодом. Это не «запрос и публикация» — человек проверяет, возражает и принимает каждое значимое суждение. ИИ — быстрый слой реализации и хранитель контекста. Инжиниринг по-прежнему ваш.
Может ли ИИ заменить DevOps-инженеров?
Нет. ИИ умеет генерировать корректные манифесты Kubernetes, диагностировать известные режимы отказа и удерживать сложную конфигурацию в контексте. Чего он не умеет — измерять ваше окружение, знать, когда что-то кажется неправильным, или отлаживать недокументированные архитектурные комбинации. Конфликт Dynatrace Operator в этом проекте потребовал человека с внутренними знаниями о продукте. Никакое количество итераций с манифестами его не нашло бы.
Что такое CLAUDE.md и почему он важен?
CLAUDE.md — живой архитектурный документ, зафиксированный в репозитории, который ИИ читает в начале каждой сессии. Он содержит характеристики железа, проектные решения, обоснование и компромиссы — общую память проекта. Без него вы восстанавливаете контекст в каждой сессии, и ИИ принимает решения, противоречащие более ранним. С ним каждый сделанный вами выбор автоматически переходит в следующую сессию.
Сколько времени занимает изучение Kubernetes с помощью ИИ?
В этом проекте: одна неделя вечеров, чтобы перейти от нулевого практического опыта к пониманию наложений kustomize, Sealed Secrets, git write-back Image Updater и сетевых служб k3s. Отличие от традиционного обучения в том, что вы строите что-то реальное на протяжении всего процесса, задаёте «почему» на каждом шаге и получаете немедленные ответы, адаптированные к вашей конкретной установке, — а не обобщённые примеры из документации.
Florian Lettner — директор по Developer Relations в Dynatrace. Мнения мои собственные.