
Дэвид Ленц
Если вы запускаете LLM на Kubernetes без маршрутизации с учётом инференса (inference-aware routing), балансировщик нагрузки, скорее всего, расходует вычислительные ресурсы впустую. Стандартное управление HTTP-трафиком слепо распределяет запросы, предполагая, что все бэкенды в кластере взаимозаменяемы. Однако бэкенды, обслуживающие модели, сохраняют состояние и в разной степени готовы к обработке конкретного запроса. В результате запросы нередко попадают к тому бэкенду, который меньше всего подходит для ответа.
Переход на Gateway API даёт более мощную основу для управления трафиком и открывает возможности для маршрутизации с учётом инференса. Inference Extension для Kubernetes Gateway API направляет запросы исходя из текущего состояния бэкендов, что, как правило, позволяет эффективнее использовать ресурсы кластера и снижать задержки.
В этой статье мы рассмотрим, как работает Inference Extension, какие стратегии маршрутизации он реализует и какие сигналы помогут отследить, правильно ли функционирует маршрутизация с учётом инференса в продакшене.
Как работает Inference Extension
Inference Extension совершенствует обычную HTTP-маршрутизацию для генеративных LLM-нагрузок: перед тем как направить запрос к конкретной точке входа, он оценивает текущее состояние каждого бэкенда. Стандартные балансировщики нагрузки разрабатывались для больших объёмов однородного веб-трафика и по умолчанию равномерно распределяют запросы. Но рабочие нагрузки LLM-инференса сильно варьируются по интенсивности запросов, вычислительным затратам и продолжительности — поэтому для эффективного распределения необходимо анализировать состояние каждого доступного бэкенда. Inference Extension использует такие сигналы, как состояние кэша «ключ–значение» (Key-Value, KV), доступность адаптеров низкорангового приближения (Low-Rank Adaptation, LoRA) и глубина очереди, чтобы выбрать оптимальный получатель для каждого запроса. Например, бэкенд с короткой очередью обработает запрос быстрее, а бэкенд с готовым KV-кэшем позволит избежать повторного вычисления общей части промпта.
Эффективно управлять этой средой и следить за ней можно, только понимая три взаимосвязанные фазы жизненного цикла запроса: первичную маршрутизацию на шлюзе, выбор конечной точки компонентом Endpoint Picker (EPP) (а также управление потоком), и непосредственно обслуживание модели.
Маршрутизация на шлюзе
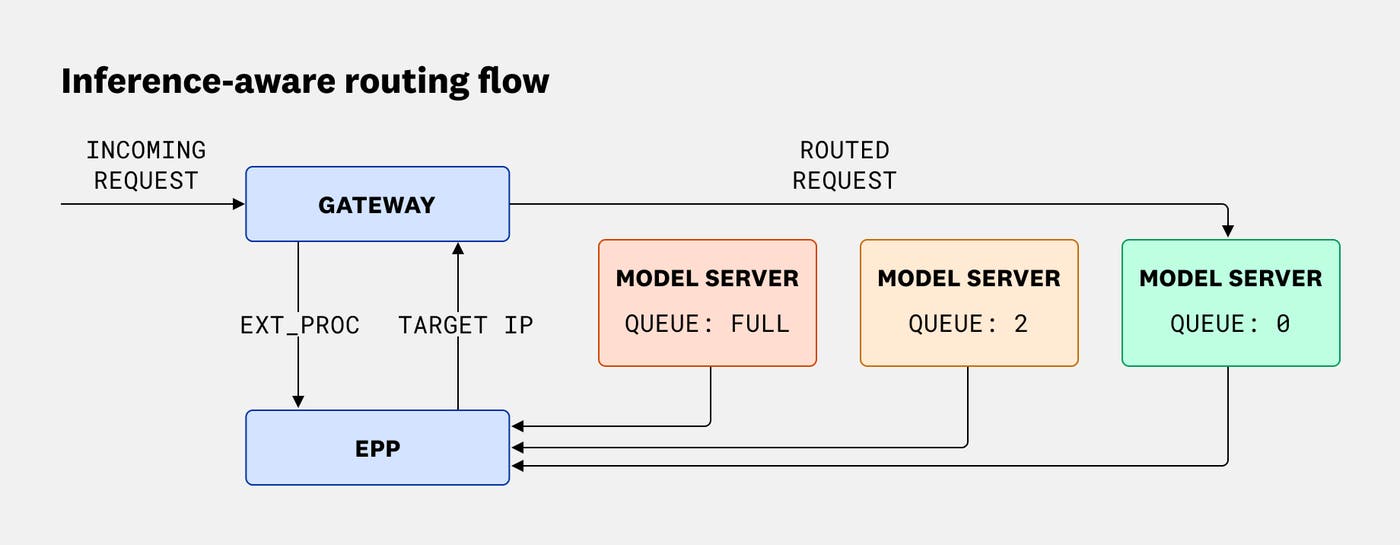
Шлюз — это первая точка контакта с входящим LLM-трафиком в кластере. Он проверяет запрос, сопоставляя его с ожидаемыми именами хостов и правилами, описанными в объекте HTTPRoute. После проверки шлюз извлекает идентификатор целевой модели — либо непосредственно из пути запроса или заголовков, либо с помощью маршрутизатора на основе тела запроса (Body-Based Router, BBR), если модель указана внутри JSON-полезной нагрузки.
Шлюз сопоставляет извлечённое имя модели с соответствующим объектом InferencePool — объектом, представляющим поды, выступающие в роли серверов моделей. Там, где обычный шлюз направил бы запрос по универсальному алгоритму вроде round-robin, Inference Extension отправляет его к тому бэкенду в пуле, который оптимально готов к обработке. Поскольку готовность отдельных подов постоянно меняется, шлюз избегает «слепой» маршрутизации и делегирует сложную задачу выбора конечной точки специализированному компоненту.
Выбор конечной точки
Чтобы определить, какой именно под в InferencePool должен получить запрос, шлюз приостанавливается и обращается к выделенному EPP пула. Поскольку планирование инференса в продакшене — крайне сложная задача, экосистема разделяет базовые API маршрутизации Kubernetes (такие как объекты InferencePool и HTTPRoute) и логику расширенного выбора конечных точек. Шлюз использует фильтр ext_proc (внешней обработки) Envoy, чтобы передать информацию о запросе продвинутому EPP — как правило, на основе специализированного планировщика производственного уровня, такого как проект CNCF llm-d, — который и принимает интеллектуальное решение о маршрутизации с учётом инференса.
EPP сначала проверяет размер полезной нагрузки запроса и отклоняет его, если тот превышает настроенные лимиты ёмкости пула, возвращая ошибку 413 Payload Too Large. Затем EPP находит оптимальную цель, постоянно анализируя телеметрию, которую предоставляют серверы моделей. При оценке и выборе лучшего бэкенда EPP балансирует несколько сигналов:
-
Доступность: EPP исключает поды, не прошедшие проверки работоспособности или готовности.
-
Глубина локальной очереди: чем короче очередь, тем быстрее запрос будет обработан.
-
Состояние адаптера: если запрос требует LoRA-адаптера, бэкенд, у которого он уже загружен, ответит без задержки холодного старта.
-
Локальность KV-кэша: сервер, у которого закэширован префикс промпта, может пропустить избыточные вычисления.
Поскольку эти факторы нередко конкурируют друг с другом — например, под с закэшированным префиксом может одновременно иметь сильно перегруженную очередь — EPP взвешивает метрики относительно друг друга, чтобы найти наиболее эффективный путь маршрутизации. Программируемая плагинная архитектура Inference Extension позволяет настраивать, как именно оценивается и взвешивается каждый сигнал. В конечном счёте EPP выбирает целевой бэкенд, но не выполняет физическую маршрутизацию — он просто возвращает IP-адрес выбранной конечной точки шлюзу, который и перенаправляет запрос.
Управление потоком
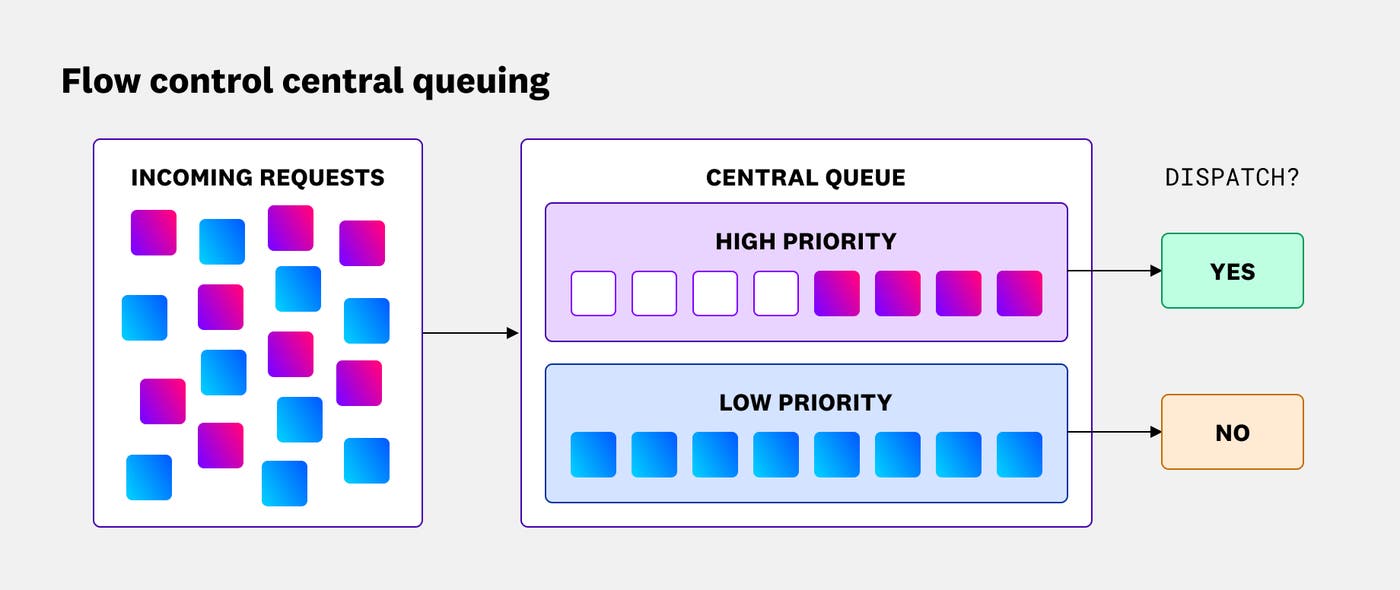
Если встроенная функция управления потоком (flow control) EPP включена, она применяет дополнительную логику принятия решений для защиты пула от исчерпания ресурсов. Оценив текущую ёмкость, управление потоком решает: немедленно отправить запрос (вернув шлюзу IP целевого пода), поставить его в центральную очередь или полностью отбросить. Без управления потоком запросы направляются напрямую в локальные очереди бэкендов, что порождает распространённую неэффективность: запрос может оказаться привязан к занятому поду и ждать там, даже если в это время освободился другой под. Управление потоком решает эту проблему, буферизуя запросы в центральной очереди EPP и отправляя их на маршрутизацию только тогда, когда подходящий бэкенд освобождается.
Чтобы GPU не простаивал между запросами, управление потоком направляет достаточно трафика для поддержания небольшого числа ожидающих запросов в локальной очереди каждого пода.
Из центральной очереди управление потоком определяет порядок отправки на основе приоритета и справедливости. Если у входящего запроса есть связанный объект InferenceObjective, управление потоком использует его приоритет для задания порядка отправки — это позволяет отдавать предпочтение интерактивному трафику, обращённому к пользователям, перед низкоприоритетными асинхронными задачами инференса, такими как пакетная суммаризация документов. Кроме того, механизм не даёт одному «шумному соседу» монополизировать очередь, обеспечивая равный доступ к вычислениям внутри одного уровня приоритета.
Если пул достигает настроенного порога насыщения, управление потоком полностью отбрасывает низкоприоритетные запросы, возвращая ошибки 429 Too Many Requests или 503 Service Unavailable, и при этом продолжает ставить в очередь запросы с нормальным приоритетом.
Архитектура центральной очереди также позволяет масштабировать ресурсы до нуля как стратегию управления затратами — особенно для асинхронных или пакетных рабочих нагрузок. Если входящих запросов нет, Kubernetes может уменьшить число GPU-бэкендов до нуля, избегая лишних расходов. Когда запросы возобновляются, они ожидают в центральной очереди, пока поднимаются поды, — это не даёт первой волне трафика завершиться с ошибкой. Хотя многоминутный холодный старт, необходимый для загрузки весов модели в видеопамять (VRAM), делает такой подход непрактичным для интерактивного обслуживания в реальном времени, он эффективен для управления затратами при фоновых задачах, где мгновенная задержка не критична, — например, при пакетной обработке обращений в службу поддержки для анализа тональности.
Обслуживание модели
Бэкенд-поды в InferencePool запускают движки для обслуживания LLM, такие как vLLM или NVIDIA Triton Inference Server. Когда шлюз направил запрос к оптимальному бэкенду, сервер модели обрабатывает промпт и начинает генерировать ответ. В процессе он сохраняет состояние механизма внимания «ключ–значение» в KV-кэш, чтобы не пересчитывать предыдущий контекст при генерации последующих токенов.
Серверу модели также может потребоваться загрузить запрошенный LoRA-адаптер в GPU-память, если он ещё не загружен.
Построение KV-кэша с нуля или загрузка весов адаптера по требованию могут заметно увеличить задержку. Поскольку EPP отслеживает телеметрию серверов моделей и понимает состояние их кэша и адаптеров, он может направлять запросы к тем бэкенд-подам, которые уже готовы ответить максимально эффективно.
Как проверить стратегии маршрутизации Inference Extension
Inference Extension реализует конкретные стратегии маршрутизации, которые помогают обеспечить производительность и экономическую эффективность LLM-нагрузок инференса на базе Kubernetes. В этом разделе описаны четыре таких стратегии, а также сигналы наблюдаемости, которые можно отслеживать для проверки их эффективности в продакшене.
Маршрутизация с учётом модели
Распространённый подход — запускать несколько AI-моделей в одном кластере Kubernetes, чтобы максимизировать использование GPU и упростить управление инфраструктурой. Для эффективного управления трафиком в такой среде используется маршрутизация с учётом модели. Чтобы её реализовать, можно определить правила HTTPRoute, которые предписывают шлюзу извлекать целевой идентификатор — например, имя базовой модели или LoRA-адаптера — и сопоставлять запрос с нужным InferencePool.
Сигналы для мониторинга:
-
Распределение маршрутизации по моделям: отслеживайте объём запросов, направляемых в каждый InferencePool, чтобы убедиться, что активность маршрутизации соответствует настроенным правилам HTTPRoute и BBR.
-
Сигналы запросов и ошибок EPP: следите за здоровьем EPP, отслеживая ошибки и задержки, которые могут указывать на неверную конфигурацию логики маршрутизации.
-
Результаты запросов и задержки со стороны пользователя: отслеживайте HTTP-коды ответов (
200против ошибок5xx) и задержки по имени модели. Это помогает быстро выявить, не испытывает ли пул конкретной базовой модели нехватки ресурсов, даже если EPP направляет запросы корректно.
Маршрутизация с учётом LoRA-адаптеров
LoRA-адаптеры — это лёгкие специализации базовой модели, адаптирующие её поведение под конкретную задачу или область, например поддержку клиентов или генерацию кода. В отличие от базовой модели, которая постоянно находится в GPU-памяти, адаптеры динамически подгружаются и выгружаются в зависимости от недавней активности. Такое постоянное переключение делает статическую маршрутизацию неэффективной. Если запрос вслепую попадает на под, у которого нет нужного адаптера, серверу приходится загружать его на лету, что приводит к штрафной задержке холодного старта.
Маршрутизация с учётом LoRA-адаптеров устраняет эту неэффективность: BBR шлюза настраивается на анализ JSON-полезной нагрузки каждого входящего запроса и извлечение имени нужного адаптера. (В запросах, совместимых с OpenAI API, это имя содержится в поле model.) Шлюз передаёт имя адаптера EPP через HTTP-заголовок, который сужает круг кандидатов до бэкендов с уже загруженным в память адаптером. Если несколько подов имеют «прогретый» адаптер, EPP оценивает дополнительные сигналы — например, глубину локальной очереди — и выбирает оптимальную цель. В итоге стратегия обеспечивает стабильное направление адаптерных запросов к наиболее подготовленному бэкенду.
Сигналы для мониторинга:
-
Концентрация маршрутизации: чтобы убедиться, что EPP успешно находит прогретые цели, проверьте, что запросы к конкретным адаптерам концентрируются на соответствующем подмножестве подов, а не равномерно распределяются по всему пулу.
-
Задержка при смене адаптеров: сопоставляйте время до первого токена (Time to First Token, TTFT) с событиями загрузки адаптеров. Если вы наблюдаете частые всплески задержки, пользователи платят штраф за холодный старт.
-
Частота загрузки и выгрузки адаптеров (thrashing): отслеживайте, как часто поды меняют адаптеры в GPU-памяти. Высокая частота загрузки и выгрузки может означать, что слишком много активных адаптеров конкурируют за слишком малый объём GPU-памяти в пуле.
Маршрутизация с учётом префиксов
Когда серверы моделей обрабатывают большие общие контексты — например, системные инструкции, документы или историю предыдущих реплик в чате, — они сохраняют результаты в локальном KV-кэше. Если последующий запрос попадёт к поду, у которого нет этого кэша, серверу придётся повторно вычислять промпт с нуля, что задержит ответ и увеличит TTFT. Чтобы избежать этой потери, маршрутизация с учётом префиксов активно направляет последующие запросы к тому поду, у которого есть нужный кэш.
Маршрутизация с учётом префиксов начинается на шлюзе. С помощью правила HTTPRoute шлюз настраивается на извлечение уникального идентификатора контекста из входящего запроса — обычно он содержится в пользовательском HTTP-заголовке (например, x-session-id). Иногда идентификатор находится в JSON-полезной нагрузке; тогда его можно извлечь с помощью BBR. Шлюз передаёт идентификатор EPP (также через HTTP-заголовок), а EPP находит бэкенды с нужными кэшированными данными, способные ответить с минимальным TTFT.
Сигналы для мониторинга:
-
Процент попаданий в KV-кэш: это наиболее прямой показатель точности маршрутизации с учётом префиксов. Стабильно высокий процент попаданий подтверждает, что шлюз корректно извлекает идентификаторы контекста, а EPP успешно сопоставляет запросы с нужными подами.
-
TTFT: если процент попаданий в кэш измеряет точность маршрутизации, то TTFT отражает реальный пользовательский опыт. Успешная маршрутизация с учётом префиксов должна удерживать средний TTFT на низком и предсказуемом уровне.
-
Использование KV-кэша: если эта метрика и TTFT одновременно высоки, возможна нехватка ёмкости — стоит рассмотреть масштабирование кластера. Если TTFT растёт при низком использовании кэша и неравномерном распределении маршрутизации, стратегия маршрутизации с учётом KV-кэша может быть подорвана устаревшими данными о состоянии бэкендов, из-за которых EPP принимает неэффективные решения.
-
Вытесненные запросы: когда GPU-кэш бэкенда заполняется, сервер модели может выгружать закэшированные префиксы в более медленную CPU-память. Увеличение частоты вытеснений — сигнал к тому, чтобы расширить пул серверов моделей.
-
Дисбаланс глубины очередей: следите за узкими местами в локальных очередях серверов моделей. Если один под хранит кэш для востребованного префикса, EPP может агрессивно направлять трафик туда, заполняя очередь и увеличивая TTFT.
Приоритет трафика и отбрасывание запросов
Максимизация использования GPU нередко предполагает использование одного InferencePool для обслуживания разных типов нагрузок инференса — например, одновременно интерактивного чата и асинхронных фоновых задач, таких как пакетная суммаризация документов. Однако поведение шлюза по умолчанию — «первым пришёл, первым обслужен» — может привести к задержкам для интерактивных приложений, если фоновые задачи занимают доступные ресурсы. Чтобы этого не допустить, можно воспользоваться управлением потоком и задать пользовательские уровни приоритета, создав объект InferenceObjective для каждой рабочей нагрузки. Затем шлюз настраивается с помощью правил HTTPRoute для сопоставления входящего трафика с соответствующим объективом — как правило, путём анализа заголовка вроде x-request-priority.
EPP соблюдает заданные приоритеты, пропуская запросы более высокого уровня вперёд в центральной очереди. Кроме того, он обеспечивает соблюдение уровней через отбрасывание запросов — активный отказ от части трафика для предотвращения исчерпания ресурсов. Например, можно настроить EPP так, чтобы он отбрасывал фоновые пакетные задания при заполнении центральной очереди на 50%, не прерывая при этом важный интерактивный трафик вплоть до 99% насыщения пула.
Сигналы для мониторинга:
-
События отбрасывания запросов: отслеживайте ответы шлюза, свидетельствующие об отбрасывании, —
429 Too Many Requestsи503 Service Unavailable. Если частота таких событий растёт, а локальные очереди глубоки и утилизация кэша высока, значит, имеет место нехватка ёмкости. Отбрасывание работает как задумано, но пул достиг физического предела — возможно, потребуется добавить ресурсы. -
Соблюдение приоритетов при насыщении: разбейте метрики задержки и процента успешных запросов по уровням трафика и сопоставьте их с общей насыщенностью пула. При пиковой загрузке бэкендов низкоприоритетный фоновый трафик должен отклоняться или приостанавливаться, а критически важные интерактивные конечные точки — сохранять близкий к 100% процент успешных ответов.
Как отслеживать маршрутизацию с учётом инференса с помощью Datadog
Чтобы проверить правильность маршрутизации с учётом инференса в продакшене, необходимо сопоставить активность шлюза и серверов моделей с состоянием базовой инфраструктуры Kubernetes. Отслеживать итоговые метрики вроде TTFT важно, но не менее необходимо следить за опережающими индикаторами по всему стеку: распределением маршрутизации на шлюзе, использованием KV-кэша на серверах моделей и давлением на узлы на инфраструктурном уровне. Вместе сигналы с уровней маршрутизации, обслуживания моделей и инфраструктуры помогают выявлять неверные конфигурации и неиспользуемые ресурсы до того, как они обернутся задержками для пользователей.
Когда производительность инференса снижается, причины, как правило, делятся на две категории: неэффективность маршрутизации или исчерпание ресурсов. Неэффективность маршрутизации возникает из-за неверно настроенных или устаревших правил HTTPRoute. Если шлюз не может извлечь необходимые данные для направления запросов к оптимальным бэкендам, запросы распределяются неудачно, и видно, как отдельные нездоровые серверы перегружены, а другие простаивают. Нехватка ёмкости кластера, напротив, проявляется как широкая насыщенность всего пула, а не изолированные горячие точки. Datadog отображает сигналы со всех трёх уровней в едином интерфейсе, позволяя с первого взгляда определить: рост TTFT связан с неверной конфигурацией маршрутизации или с нехваткой ресурсов во всём пуле.
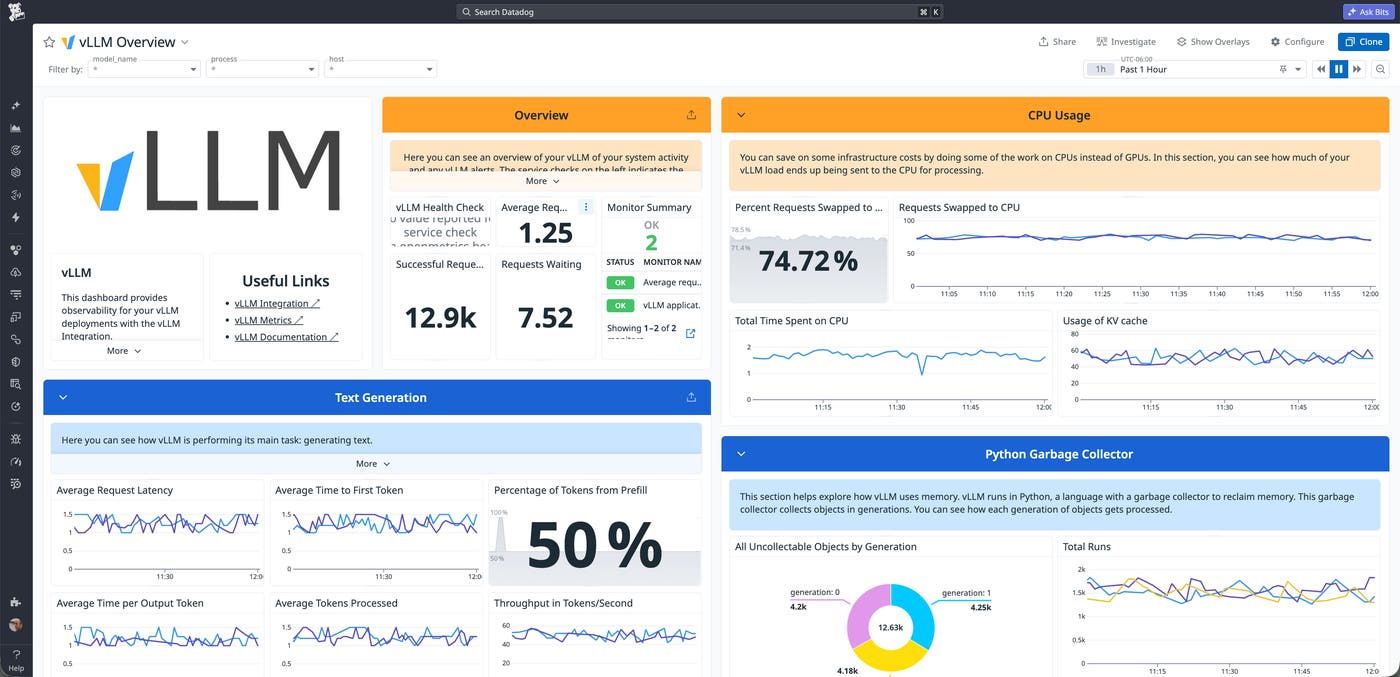
Интеграция Datadog с vLLM
Интеграция Datadog с vLLM собирает критически важные метрики состояния бэкендов: использование KV-кэша, количество активных и ожидающих запросов, вытесненные запросы и задержки. Готовый (OOTB) дашборд визуализирует эти ключевые показатели, позволяя проактивно следить за работой серверов моделей.
-
vllm.time_to_first_token.seconds: главная результирующая метрика для оценки эффективности маршрутизации. Если TTFT вырос, а очереди распределены неравномерно, уровень маршрутизации, скорее всего, не справляется с концентрацией трафика на прогретых подах. -
vllm.gpu_cache_usage_perc: рост использования кэша на всех бэкендах сигнализирует о давлении в масштабах пула. Низкое использование при высоком TTFT указывает на неверную конфигурацию маршрутизации. -
vllm.num_requests.runningиvllm.num_requests.waiting: отслеживайте глубину очереди на каждом бэкенде отдельно — это помогает диагностировать дисбалансы маршрутизации. -
vllm.num_requests.swapped: повышенная частота вытеснений свидетельствует о нехватке GPU-памяти на бэкендах и возможной необходимости масштабирования пула.
Интеграция Datadog с OpenMetrics
Интеграция Datadog с OpenMetrics позволяет собирать сигналы наблюдаемости с любой Prometheus-совместимой конечной точки, включая Inference Extension. Вы можете автоматически собирать метрики расширения и загружать их как пользовательские метрики для визуализации и настройки алертов в Datadog — это помогает обнаруживать проблемы до того, как ухудшится задержка для конечных пользователей. Например, можно отслеживать сквозное время ответа для выявления накладных расходов на уровне расширения, следить за распределением маршрутизации для обнаружения дисбалансов и считать события отбрасывания запросов как подтверждение исчерпания ресурсов.
-
inference_objective_request_duration_seconds: отслеживает сквозное время ответа для выявления накладных расходов на уровне расширения. -
inference_pool_per_pod_queue_size: показывает распределение трафика. Неравномерное распределение может подтверждать успешную концентрацию трафика на прогретых целях, тогда как локализованные всплески могут указывать на дисбаланс глубины очереди на отдельном поде, хранящем кэш. -
inference_extension_flow_control_request_queue_duration_seconds.countс фильтрамиoutcome="Rejected"илиoutcome="Evicted": напрямую измеряет события исчерпания ресурсов и отбрасывания запросов.
GPU-мониторинг в Datadog
Метрики vLLM рассказывают о производительности движка обслуживания, а возможности GPU-мониторинга Datadog дают глубокую видимость в физическое оборудование, на котором работают модели. Вместе с интеграцией Datadog с NVML, мониторинг GPU позволяет отслеживать телеметрию на уровне железа: утилизацию GPU, выделение VRAM, энергопотребление и тепловые состояния по всему парку оборудования.
VRAM — конечный ресурс, и такие метрики, как gpu.memory.usage и nvml.fb_used, являются критическими индикаторами давления на железо. Поскольку интеграция с vLLM не собирает прямую метрику числа загруженных LoRA-адаптеров, давление на VRAM служит косвенным показателем насыщения адаптерами. Если утилизация VRAM стабильно высока и TTFT тоже повышен, серверы, вероятно, держат в памяти слишком много простаивающих адаптеров, что может приводить к вытеснению и сокращению доступного пространства для кэша.
Для проверки общего состояния железа можно следить за nvml.gpu_utilization, gpu.power.usage и gpu.temperature. Если сигналы с уровней маршрутизации и обслуживания моделей указывают на проблему, но эти аппаратные метрики в норме, можно с уверенностью заключить, что причина — в маршрутизации или конфигурации, а не в физическом ограничении ёмкости.
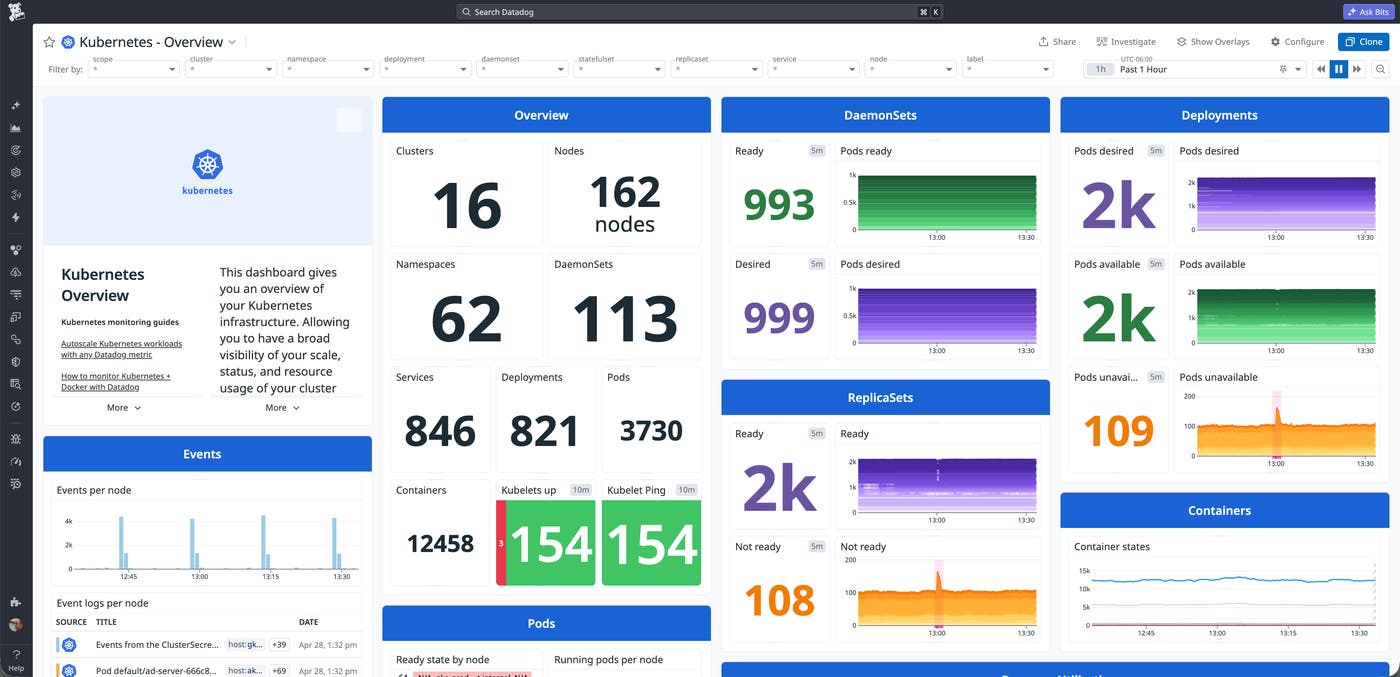
Мониторинг Kubernetes в Datadog
Мониторинг Kubernetes в Datadog обеспечивает базовый контекст среды как для маршрутизации, так и для обслуживания моделей. Он помогает определить: снижение производительности нагрузок инференса обусловлено проблемой маршрутизации или на самом деле вызвано нестабильностью подов, давлением на узлы, исчерпанием ресурсов или более широкими ограничениями кластера.
Отслеживая перезапуски подов (kubernetes.containers.restarts), события OOMKill (kubernetes_state.container.terminated) и статус узлов (kubernetes_state.node.status), можно быстро проверить состояние оркестрации рабочих нагрузок. Если вы наблюдаете ошибки или задержки в процессе инференса, но здоровье подов и статус узлов в норме — проблема, скорее всего, в неверной конфигурации маршрутизации. Если же эти метрики Kubernetes деградированы, пул достиг настоящего физического предела.
Кроме того, с помощью Container Monitoring в Datadog можно получить видимость в пользовательские ресурсы (CRD) Inference Extension. Отслеживание объектов InferencePool и InferenceObjective, управляющих LLM-трафиком, позволяет убедиться, что задуманная архитектура маршрутизации действительно развёрнута и работает как задумано на уровне кластера.
Проверяйте маршрутизацию с учётом инференса с помощью Datadog
Inference Extension для Kubernetes Gateway API реализует маршрутизацию с учётом инференса для эффективного управления динамическими LLM-нагрузками. Отображая состояние бэкендов — использование KV-кэша и готовность LoRA-адаптеров, — эта архитектура помогает максимально использовать ёмкость GPU и снижает TTFT. Вы можете отслеживать эти среды с помощью Datadog, объединяя сигналы от шлюза, серверов моделей и инфраструктуры — это позволяет мгновенно разграничивать неверные конфигурации маршрутизации и физические ограничения ёмкости. Подробнее об интеграциях Datadog читайте в документации: интеграция с vLLM, интеграция с OpenMetrics и мониторинг Kubernetes.
Если у вас ещё нет аккаунта, вы можете зарегистрироваться и получить 14-дневный бесплатный доступ.